Como já “discutimos” recentemente, e vamos continuar a fazê-lo, o todo-poderoso Google está para introduzir uma nova sistemática para distribuição de seus anúncios dirigidos. O sistema é chamado FLoC, sigla em inglês para Aprendizagem Federada sobre Coortes, e ele pretende substituir os notórios ‘cookies’ em nossos dispositivos. Essa sigla vai passar a fazer parte do cotidiano de todos na rede, portanto o aprendizado virá automaticamente com o tempo. O foco aqui é estimular a discussão dialética dos prós e contras entre os tecnologistas militantes e aspirantes. Assim, delineio abaixo alguns comentários sobre o assunto, tentando enquadrar as duas correntes.

Antes, algumas definições rápidas:
Cookies de site: são os cookies comuns, armazenados pelos sites em seu navegador. Eles podem ser usados para configurar preferências nos sites visitados, mas são rotineiramente abusados para rastreamento.
Cookies de terceiros: são como os cookies de site, mas usados unicamente para rastreamento. O cruzamento das informações que eles carregam revela quem você é e o que está fazendo (largamente alimentados por Smartphones).
FLoC: armazenado em seu dispositivo, rastreia a atividade no navegador e coloca o usuário em um determinado grupo, ou, digamos, um “balde”… Google alega que esse sistema é mais anônimo do que os cookies de terceiros, porque apenas o Google terá a informação sobre seu histórico. Mas mesmo assim, esses “baldes” ainda dizem tudo sobre você. Não há limite à informação que esses baldes podem conter e nem a como ela é usada. Além disso, o Google marca seu ID em todos os navegadores, de forma que é muito fácil converter esse “rastreamento anônimo” de volta à ‘persona’ identificável do usuário
O FLoC classifica os usuários em “coortes” [grupos] com base em seus interesses percebidos. A coorte, que reside em seu computador, é então passada ao site que você visita, para que ele possa segmentar anúncios para você, usando as informações que sua coorte dá a ele. Antes os sites faziam isso usando os chamados “cookies de terceiros.”
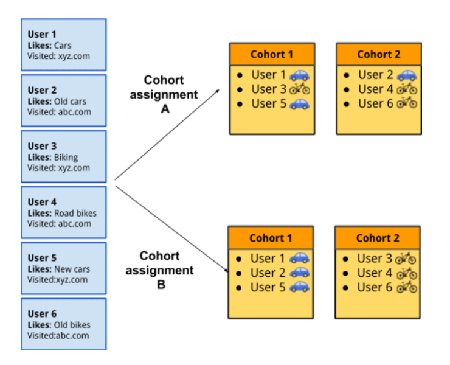
Basicamente, o problema para o Google é que os cookies de terceiros estão sendo mortos pelas políticas contemporâneas de privacidade dos navegadores e as tecnologias alternativas a eles dificultam o rastreamento adequado de todos. Então o Google é levado a construir o FLoC como uma alternativa fácil para contornar o bloqueio dos navegadores aos cookies de terceiros. Com o FLoC, um site qualquer não poderá usar cookies de terceiros para rastrear os usuários diretamente. Mas então, você não só ainda tem o rastreamento, mas também dá agora muito mais poder ao Google, que é o dono da tecnologia. Todos os seus gostos pessoais e comportamentos estão lá para para que eles façam com esses dados o que bem entenderem.
O Google afirma que esse esquema é melhor para a privacidade, porque todo o rastreamento que interessa é feito no navegador e mantido local [em seu computador]. O site só recebe um identificador geral de coorte, e como as coortes conterão milhares de usuários, elas serão de uso limitado para o rastreamento de indivíduos particulares.
Existem inúmeros problemas com essa tese. Para começar, a implementação é o que chamaríamos de “meia-boca”, com o sistema de atribuição de coorte não sendo suficientemente resistente à deanonimização. Um adversário poderia simular milhares de sessões de navegação e observar quais identificadores de coortes resultam delas. Adicionalmente, se um adversário controla vários sites populares, ele pode usá-los para forçar usuários a frequentar coortes selecionadas.
E há a questão dos temas “sensíveis”. O Google afirma que vai garantir que coortes sensíveis sejam bloqueadas. Portanto, não haverá nada relativo a religião, orientação sexual e semelhantes. Mais uma vez, o problema é que a listagem dos grupos sensíveis que eles vão ter é incompleta e, para piorar, baseada em tabus e problemas sociais ocidentais. De fato, é muito provável que coortes abusivas sejam criadas, colocando as minorias em perigo em regimes autoritários e ditaduras.
O FLoC também quebra o modo privado de navegação. Por padrão, o FLoC envia um valor nulo ao servidor do site quando não há dados suficientes para atribuir um usuário a uma coorte ou quando ele estiver no modo privado de navegação. Isso dá aos adversários uma maneira de detectar, por dedução, a navegação privada.
O Outro Lado

É tentador apenas dizer “sem cookies de terceiros e sem FLoC! Queremos a web privada!”. A realidade é que, se essa abordagem for algum dia adotada por navegadores, os custos seriam empurrados de volta para o usuário de alguma forma. O FLoC não é perfeito, mas é melhor que os cookies, e é, pelo menos, a ideia geral correta para uma solução que possa manter o atual sistema suportado por anúncios rolando, evitando os problemas de privacidade mais egrégios.
Se os usuários / navegadores / plataformas de conteúdo não puderem chegar a algum tipo de consenso com os anunciantes em termos do equilíbrio privacidade versus “anúncios dirigidos“, os anunciantes vão anunciar menos – o que vai prejudicar muitos sites usados por muitas pessoas – ou eles exigirão dos provedores de conteúdo que forneçam soluções de segmentação de anúncios com propriedades ainda piores: coisas como “Login com o Facebook para ver este conteúdo“. Adicionalmente, sites precisarão de mais anúncios (e anúncios mais intrusivos) para gerar o mesmo tanto de receita publicitária.
Epílogo
Pessoalmente, eu adoraria ver algum tipo de sistema de micro-pagamentos tomar o lugar da web suportada por anúncios – mas essa ideia parece ser fortemente rejeitada pela maioria dos usuários, julgando-se pela incrível quantidade de ítens “grátis” consumidos diariamente na rede. A não ser que haja uma mudança significativa no panorama, temo que certas pessoas e instituições vão, como sói acontecer, rejeitar uma solução imperfeita (FLoC) em favor de algo ainda não conhecido e muito pior.