Para os padrões de hoje não é grande coisa, mas no dia 18 de novembro de 1994 foi algo ENORME! Nesse dia, quando a internet ainda estava engatinhando, os Rolling Stones se tornaram a primeira banda a transmitir um de seus shows pela “rede mundial de computadores”.
A banda em um show não identificado – Imagem: Dallas Morning News (Fair Use)
Os Stones transmitiram pela web 20 minutos de sua apresentação no Cotton Bowl em Dallas (em sua turnê Voodoo Lounge) usando o sistema o Multicast BackBone [MBone]. Em universidades e laboratórios de pesquisa com conexões MBone, os fãs se aglomeraram em torno das telas dos computadores para assistir ao vídeo de varredura lenta. As críticas decididamente não foram entusiásticas devido à baixa qualidade da imagem.
Os Stones tocaram “Not Fade Away”, “Tumbling Dice”, “You Got Me Rocking”, “Shattered” e “Rocks Off”. No meio do set, Mick Jagger anunciou ao vivo para os fãs em Dallas e aqueles conectados virtualmente através do backbone multicast (MBone):
“Eu quero dar as boas-vindas a todos que subiram na internet esta noite e entraram no MBone. Espero que o site não caia”
Desde então, o mundo do streaming de vídeo sofreu muitas mudanças. Na década de 1990, enquanto a indústria lutava com desafios técnicos de tráfego de vídeo multicast, os protocolos de download HTTP e streaming com estado [stateful] começaram a ter protagonismo. Em 1996, Netscape, RealNetworks, Borland, NeXT e 36 outras empresas deram seu peso ao Real Time Streaming Protocol (RTSP).
Em 2002, a Macromedia lançou o Flash Communication Server MX 1.0 com suporte para o que se tornaria o protocolo mais amplamente adotado para streaming orientado a conexão, o Real Time Messaging Protocol (RTMP). E em 2005, o YouTube foi lançado, lembrando aos usuários da internet que, pelo menos para vídeos curtos, o download progressivo por HTTP ainda era uma opção muito viável.
Então, em 2008, a Microsoft introduziu o Smooth Streaming, uma abordagem híbrida para transmissão de vídeo que oferecia protocolos de streaming personalizados, aproveitando-se do protocolo HTTP e da infraestrutura de rede existente. Em agosto do mesmo ano, a Microsoft e a NBC usaram o Smooth Streaming para transmitir ao vivo cada minuto de cada evento dos Jogos Olímpicos de Pequim para mais de 50 milhões de telespectadores em todo o mundo. Em um único evento, o “Modern Streaming” provou que a Internet era capaz de produzir vídeos escalonáveis, confiáveis e com qualidade de transmissão.
Nos anos que se seguiram, o Modern Streaming rapidamente ganhou impulso, com a Apple introduzindo o HTTP Live Streaming (HLS), a Adobe lançando o HTTP Dynamic Streaming (HDS) e as principais empresas de mídia e streaming colaborando no MPEG-DASH. As inovações em Smooth Streaming, HLS, HDS e DASH geraram um ressurgimento na transmissão de vídeo baseada em HTTP e hoje estão remodelando a forma como as empresas e universidades transmitem conteúdo de mídia em suas redes.
Descanse em paz, Charlie Watts, baterista de Jazz, Rock’n’roller e Gentleman. 1941-2021 – Imagem: Rolling Stones – divulgação
O poder de computação ao alcance das pessoas começou a crescer rapidamente, aos trancos e barrancos, na virada do milênio, quando as unidades de processamento gráfico (GPUs) começaram a ser aproveitadas para cálculos não gráficos, uma tendência que se tornou cada vez mais difundida na última década.
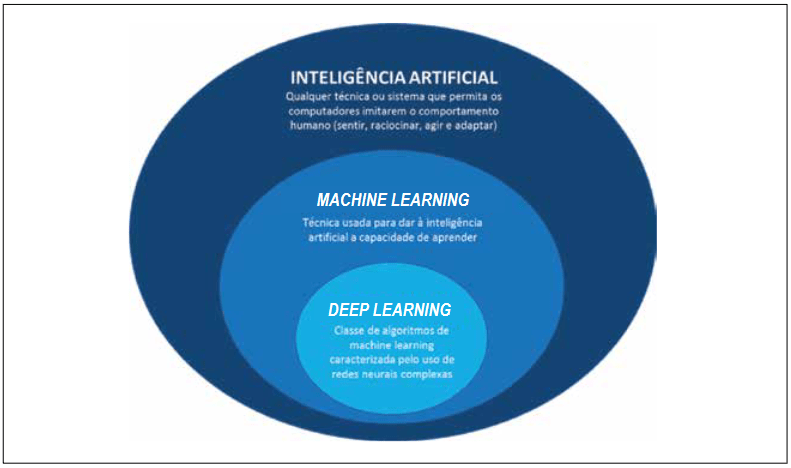
Ainda não temos uma Teoria da Mente, que possa nos dar uma base para a construção de uma verdadeira inteligência senciente. Aqui a distinção entre as disciplinas que formam o campo da Inteligência Artificial
Mas as demandas da computação de “Aprendizado Profundo” [Deep Learning] têm aumentado ainda mais rápido. Essa dinâmica estimulou os engenheiros a desenvolver aceleradores de hardware voltados especificamente para o aprendizado profundo [o que se conhece popularmente como ‘Inteligência Artificial’], sendo a Unidade de Processamento de Tensor (TPU) do Google um excelente exemplo.
Aqui, descreverei resumidamente o processo geral do aprendizado de máquina. Em meio a reportagens cataclísmicas anunciando o iminente desabamento do Céu, precisamos saber um pouco sobre como os computadores realmente executam cálculos de redes neurais.
Visão geral
Quase invariavelmente, os neurônios artificiais são ‘construídos’ [na verdade eles são virtuais] usando um software especial executado em algum tipo de computador eletrônico digital.
Esse software fornece a um determinado neurônio da rede várias entradas e uma saída. O estado de cada neurônio depende da soma ponderada de suas entradas, à qual uma função não linear, chamadafunção de ativação, é aplicada. O resultado, a saída desse neurônio, torna-se então uma entrada para vários outros neurônios, em um processo em cascata.
As camadas de neurônios interagem entre si. Cada círculo representa um neurônio, em uma visão muito esquemática. À esquerda (em amarelo) a camada de entrada. Ao centro, em azul e verde, as camadas ocultas, que refinam os dados, aplicando pesos variados a cada neurônio. À direita, em vermelho, a camada de saída, com o resultado final.
Por questões de eficiência computacional, esses neurônios são agrupados em camadas, com neurônios conectados apenas a neurônios em camadas adjacentes. A vantagem de organizar as coisas dessa maneira, ao invés de permitir conexões entre quaisquer dois neurônios, é que isso permite que certos truques matemáticos de álgebra linear sejam usados para acelerar os cálculos.
Embora os cálculos de álgebra linear não sejam toda a história, eles são a parte mais exigente do aprendizado profundo em termos de computação, principalmente à medida que o tamanho das redes aumenta. Isso é verdadeiro para ambas as fases do aprendizado de máquina:
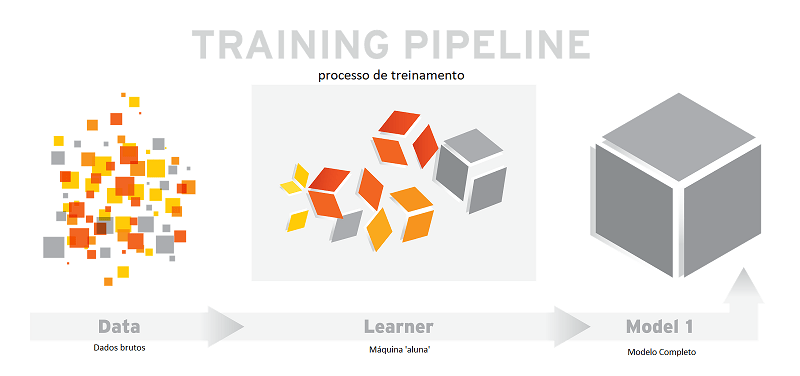
O treinamento – processo de determinar quais pesos aplicar às entradas de cada neurônio.
A inferência – processo deflagrado quando a rede neural está fornecendo os resultados desejados.
Concepção do processo de treinamento de máquina, dos dados brutos, à esquerda, ao modelo completo.
Matrizes
O que são esses misteriosos cálculos de álgebra linear? Na verdade eles não são tão complicados. Eles envolvem operações com matrizes, que são apenas arranjos retangulares de números – planilhas, se preferir, menos os cabeçalhos de coluna descritivos que você encontra em um arquivo Excel típico.
É bom que as coisas sejam assim, porque o hardware de um computador moderno é otimizado exatamente para operações com matriz, que sempre foram o pão com manteiga da computação de alto desempenho – muito antes de o aprendizado de máquina se tornar popular. Os cálculos matriciais relevantes para o aprendizado profundo se resumem essencialmente a um grande número de operações de multiplicação e acumulação, em que pares de números são multiplicados entre si e seus produtos somados.
Ao longo dos anos, o aprendizado profundo foi exigindo um número cada vez maior dessas operações de multiplicação e acumulação. Considere LeNet, uma rede neural pioneira, projetada para fazer classificação de imagens. Em 1998, demonstrou superar o desempenho de outras técnicas de máquina para reconhecer letras e numerais manuscritos. Mas em 2012 o AlexNet, uma rede neural que processava cerca de 1.600 vezes mais operações de multiplicação e acumulação do que o LeNet, foi capaz de reconhecer milhares de diferentes tipos de objetos em imagens.
Gráfico tridimensional ilustrando o processo de inferência, partindo de dados brutos dispersos (embaixo à direita) até o refinamento final (após muitas iterações de inferência), onde o resultado (ou predição) é obtido.
Aliviar a pegada de CO2
Avançar do sucesso inicial do LeNet para o AlexNet exigiu quase 11 duplicações do desempenho de computação. Durante os 14 anos que se passaram, a lei de Moore ditava grande parte desse aumento. O desafio tem sido manter essa tendência agora que a lei de Moore dá sinais de que está perdendo força. A solução de sempre é simplesmente injetar mais recursos – tempo, dinheiro e energia – no problema.
Como resultado, o treinamento das grandes redes neurais tem deixado uma pegada ambiental significativa. Um estudo de 2019 descobriu, por exemplo, que o treinamento de um determinado tipo de rede neural profunda para o processamento de linguagem natural emite cinco vezes mais CO2 do que um automóvel durante toda a sua vida útil.
Os aprimoramentos nos computadores eletrônicos digitais com certeza permitiram que o aprendizado profundo florescesse. Mas isso não significa que a única maneira de realizar cálculos de redes neurais seja necessariamente através dessas máquinas. Décadas atrás, quando os computadores digitais ainda eram relativamente primitivos, os engenheiros lidavam com cálculos difíceis como esses usando computadores analógicos.
À medida que a eletrônica digital evoluiu, esses computadores analógicos foram sendo deixados de lado. Mas pode ser hora voltar a essa estratégia mais uma vez, em particular nestes tempos em que cálculos analógicos podem ser feitos oticamente de forma natural.
Nos próximas postagens vou trazer os mais recentes desenvolvimentos em fotônica aplicada ao aprendizado de máquina – em uma arquitetura analógica! Estamos, sem dúvida, vivendo tempos interessantes neste campo promissor.
A ideia que parece perpassar o ambiente corporativo hoje é que ser mais produtivo, seja o que for que isso implique, não precisa ser automaticamente produto da compreensão dos problemas ou da verdade. Os interesses que promovem a IA têm pouco ou nenhum desejo de encontrar ou distribuir a verdade. Canibalizar textos digitais sem considerar o que os torna verdadeiros é uma receita para a desintegração do conhecimento, não a produção ou reflexão dele.
Para cumprir sua promessa, a inteligência artificial precisa aprofundar a inteligência humana. Isso é certamente verdade… e isso certamente NÃO vai acontecer. Veja o que a internet fez com a mente humana. Reduziu a maioria das pessoas a viciados em cocaína eletrônica pixelizada, cujas habilidades de pensamento crítico, conhecimento de história, habilidades de linguagem e capacidade de atenção despencaram coletivamente.
Antes da internet, tínhamos milhares de jornais locais robustos relatando notícias locais, unindo comunidades e mentes locais como cola. Tudo isso desapareceu quase da noite para o dia, e agora ficamos com um punhado de conglomerados nacionais que compraram a maioria dessas instituições e as reduziram a esqueletos de seus antigos eus.
As ‘notícias’ que as pessoas consomem hoje vêm de algoritmos nas mídias sociais. Os jornais foram substituídos principalmente por junk news, que é perfeitamente semelhante à junk food e seus efeitos deletérios sobre os seres humanos.
A internet foi colonizada pelos piores instintos da humanidade e reduziu a mente humana a escombros do Facebook, Instagram, realidade alternativa, violência, conspiração e êxtase religioso… todos exemplos robustos de involução humana. A ação conjunta da ‘Inteligência Artificial’ e um grupo conhecido de atores humanos maus e gananciosos têm potencial para acelerar a involução humana e nos levar ao penhasco da destruição. Manter nossas habilidades de pensamento crítico humano é nossa única esperança… e pode não ser suficiente.
Derivativos
Os Grandes Modelos de Linguagem – GML [Large Language Models, LLM] podem ser entendidos como Títulos de Informação garantidos por hipotecas: um vasto número de fontes cortadas em pedaços e remontadas em composições convincentemente realistas que parecem, para todos os propósitos, funcionar por conta própria. Mas, como aprendemos na crise de 2008, os derivativos não são melhores do que aquilo de que são derivados, e essa verdade reduz muito a confiabilidade no que esse tipo de IA é capaz.
O problemas dos rótulos
Nada dessensibiliza mais uma pessoa quanto ao romantismo do Fim do Mundo provocado pela Skynet do que passar horas colocando quadradinhos ao redor de bois e vacas em imagens fotográficas. Na labuta da rotulação de dados – um penoso processo manual que está na base de todos os sistemas de inteligência artificial, você começa ver as entranhas do sistema: a inteligência artificial não funciona sem humanos na máquina. É notável que não seja dada maior atenção ao trabalho dos rotuladores, humanos reais, trabalhando na maioria das vezes fora dos limites da dignidade. Ao conhecer esse processo uma perspectiva mais clara do que está por baixo do capô aparece.
Os ‘quadradinhos de rótulo’, colocados tediosamente por humanos, são essenciais na modalidade de AI chamada ‘visão de computador’. São os rótulos que ensinam ao computador, por meio de muitas repetições, o que é uma vaca. Imagem: Vox Leone
Em tempo: neste ponto chamo a atenção para a ferramenta que estou desenvolvendo para automatização das tarefas de rotulação de imagem [o nome da disciplina é ‘anotação’] para modelos de visão de computador, que disponibilizo em nosso github: Auto-Annotate-BR. Estou internacionalizando e adaptando a ferramenta. Creio que esse seja o primeiro trabalho do gênero em português. Dê uma olhada, e, se possível, me dê uma ajuda na divulgação e compartilhamento.
Não exatamente como previsto
Quanto à suposta emergência da Inteligencia Artificial Geral – IAG [Artificial General Inteligence – AGI] a partir das redes neurais da Microsoft, Meta e Google, o burburinho que está acontecendo com ChatGPT e similares não lembra em nada o que foi profetizado por Nick Bostrom, o grande papa da superinteligencia: a partir de uma centelha inicial a entidade inteligente cresceria exponencialmente como um Big Bang, tomando rapidamente todas as redes conectadas. Se o que vemos é a AGI ela é de um tipo ainda não descrito em qualquer cenário, certamente não o de Bostrom.
Replicar o cérebro humano
Como racionalista, me inclino a concordar com Max Tegmark que a consciência é independente do substrato físico, ou seja, ela não depende necessariamente do tecido mole do qual é feito nosso cérebro. Outras bases físicas [como o silício + metais] convenientemente trabalhadas podem também servir. Considero as redes neurais uma conquista intelectual impressionante. Me parece claro que AGI vai surgir das redes neurais, uma vez que ela assim o faz nas formas de vida que conhecemos.
Os sistemas de camadas em nossas redes neurais artificiais são uma analogia bastante apta do funcionamento real do cérebro. Pelas explorações realizadas até o momento via imageamento, sabemos que as conexões neurais humanas ocorrem em áreas especializadas do cérebro, não exatamente em camadas físicas organizadas, como em uma rede neural artificial, mas em topologias neurais arranjadas em 3d, nas mais diversas configurações.
Exemplo simplificado de rede neural. O peso da sinapse de saída para o neurônio de adição (+) deve ser calculado antes que o neurônio de multiplicação (*) possa calcular o peso de sua sinapse de saída. Mesmo redes neurais relativamente “simples” têm centenas de milhares de neurônios e sinapses; é bastante comum uma rede neural ter mais de um milhão de arestas. Em nosso cérebro os neurônios e sinapses são trilhões. Fonte:https://medium.com/tebs-lab/deep-neural-networks-as-computational-graphs-867fcaa56c9
Para se equiparar totalmente ao modelo humano, a AGI baseada em redes neurais vai necessitar receber, dinamicamente, informação de sensores de todos os tipos [para poder tomar amostras de pelos menos cinco grandes categorias de estímulos físicos, como nós]. Aqui também vemos um paralelo com a a inteligencia natural, pois nós também rotulamos a realidade, a partir das informações dos sentidos. Chamamos os rótulos que aprendemos de ‘conceitos’ [ML classes?]; expressamos nos rótulos nossa conceitualização do mundo, também obtida através de reforço.
As redes neurais parecem ser, de fato, o caminho para a AGI. Mas não estamos nem perto de conseguir essas coisas. Se queremos chegar ao nível das redes neurais que carregamos em nossas cabeças temos que aprender mais sobre o papel das outras estruturas cerebrais, como as células gliais, que sabidamente influem na ativação e moderação das sinapses do cérebro humano [que correspondem aos ‘pesos’ nas redes neurais artificiais].
Deixando a imaginação vagar sem amarras, é possível conjecturar que as redes neurais sejam estruturas fundamentais no universo, e que a consciência e a inteligencia emerjam de algumas configurações topológicas de processamento neural [incluindo as citadas células gliais e outras estruturas].
O inimigo é outro
As redes neurais, mesmo as relativamente primitivas redes atuais, baseadas em estatística e poder de computação, vão provocar uma drástica correção em vários setores da vida. Milhões perderão empregos e meios de subsistência. Contudo, cavaleiros do apocalipse mais poderosos [e com um timing melhor] são as redes sociais. Talvez a dissolução da sociedade civilizada por conta da ação insidiosa da mídia social já tenha começado e nos encontremos irremediavelmente além do horizonte de eventos.
Eu tenho argumentado que as mídias sociais – assim como um grande número de blogs – permitem que as pessoas se distorçam de maneira doentia para obter lucro.
Quando a reinvenção pessoal para o sucesso comercial se torna a norma, é fácil perder de vista as próprias necessidades enquanto se concentra em atender às demandas insaciáveis do público. Há uma grande diferença entre apresentar bem-estar para um público e realmente tê-lo alcançado.
O ciclo implacável de vender e reembalar o ego não apenas cria uma variedade estonteante de personas a serem mantidas, mas também estabelece as bases para uma crise existencial quando a demanda por essa identidade curada diminui.
A morte da ‘momblogger‘
Este mês de maio viu o passamento, aos 47 anos, de Heather Armstrong, uma das primeiras blogueiras a documentar os altos e baixos da maternidade. Armstrong, conhecida por seus fãs pelo nome de seu site, Dooce, morreu por suicídio, de acordo com seu parceiro, Pete Ashdow – como também fartamente noticiado na mídia de língua inglesa.
Nos anos finais de sua vida, Armstrong já era conhecida postumamente, por assim dizer; escrevendo no Instagram para uma fração de seu antigo público; seu passado mais conhecido do que seu presente. Tenho certeza que muitos bloguistas, podcasters e os variados especialistas virtuais de hoje são capazes de entender o drama de Heather, uma vez que compartilham, em graus variados, a mesma experiência agridoce. Nas redes sociais, inúmeras pessoas se entregaram inteiramente ao jogo da criação de conteúdo pessoal – fazendo jogadas que invariavelmente levarão a retornos decrescentes, até que não tenham mais jogadas a fazer.
Armstrong via a si mesma como uma empresa dedicada ao melhoramento pessoal. Mas será que ela realmente escrevia para seu público ou dialogava consigo mesma? Seu trabalho autobiográfico final, The Valedictorian of Being Dead, foi projetado para consumo, e não para grande voos filosóficos ou qualquer tipo de debate sério. Portanto, a questão permanece: quem ela realmente tentava influenciar?
Se você projetar sua vida para o consumo, ela será consumida. Longe de pretender julgar instâncias alheias, isto é um alerta – e para mim mesmo um mantra, que repito como expiação de fracassos, ou como desculpa. E o que acontece depois? É tão surpreendente que o vazio que sobra seja aterrorizante? Quando sua existência é uma piada pronta, uma boa história paga, uma anedota fofa, uma opinião – reveladora – sobre o que fazer e não fazer… Quando sua experiência de vida se torna simplesmente uma busca por qualquer conteúdo novo e monetizável, e suas escolhas são feitas com uma piscadela e um aceno de cabeça para os assinantes. O que você se torna quando não há mais nada para rir, zombar, satirizar ou ridicularizar? Quem é você depois de ter vendido tudo? O que realmente resta?
E você se pergunta: “Como cheguei aqui?”. “Para onde vai esta estrada?” E você pode se perguntar: “Estou certo? Estou errado?” E você talvez diga diante do espelho: “Meu Deus, o que eu fiz?”
Não foi a primeira e claramente não será a última vez que um ser humano descobre que a objetificação absoluta do Self é uma espécie de barganha faustiana, como a destilada em ‘Dorian Gray’. No fim, parece que a triste Sra. Armstrong achou o preço final alto demais para continuar a pagar. Que ela esteja em paz e que seu martírio não tenha sido em vão.
Notícias dando conta de que a Samsung pensa em substituir Google por Bing em sua linha de smartphones enviou ondas de choque por toda a web este mês.
Imagem: Domínio Público
Durante anos, o Bing foi um mecanismo de buscas secundário. Mas tornou-se muito mais interessante para os especialistas da indústria quando recentemente adicionou uma nova tecnologia de inteligência artificial. A reação do Google à ameaça da Samsung foi de “pânico”, de acordo com mensagens internas analisadas pelo The New York Times. Estima-se que US$ 3 bilhões em receita anual estarão em jogo com o contrato da Samsung. Outros US$ 20 bilhões estão vinculados a um contrato semelhante da Apple que será renovado este ano.
Surpresa
Se você tivesse me dito há 3 meses que o Bing seria uma séria ameaça ao Google, eu teria rido. Esse é o impacto que a integração do ChatGPT teve para o Bing – da noite para o dia.
Se a história de 48 anos da Microsoft mostra alguma coisa, é que eles podem produzir produtos abaixo da média, experimentar inúmeras falhas, fazer investimentos e aquisições ruins e até mesmo arruinar produtos (por exemplo, Skype), mas permanecem resilientes e bem-sucedidos.
A falha do Google me surpreende. Como uma empresa com tanto dinheiro, tantos engenheiros maravilhosos, não consegue gerar uma fonte de receita que não seja o mecanismo de busca? Sempre acompanhei as notícias sobre os programas de IA do Google. Como diabos foi a Microsoft quem apareceu com o o maior sucesso em IA, OpenAI?
Parece claro que o Google ficou muito grande e desalinhado. O Google coloca muita ênfase em habilidades (de codificação) que não são necessárias para a maior parte do trabalho realizado e não enfatiza a seleção da capacidade de criar coisas que as pessoas desejam usar. Eles tiveram que criar uma linguagem de programação simplificada (Go) porque muitos de seus novos graduados em codificação não conseguiam lidar com C ++.
Talvez seja excessivamente reducionista, mas também acho que muitos dos problemas do Google se resumem à sua autoimagem. Até hoje, eles estão presos em 2006, quando todo mundo os via como “legais”, “inovadores”, “não Micro$oft” e “não maus”. A maioria dos pessoas comuns não acredita mais nessas coisas e apenas vê o Google como a coisa padrão para procurar coisas em seus telefones.
O Google acreditava que poderia crescer rapidamente e se estruturar com o caos ordenado porque eram os escolhidos. Sua “hubris” permitiu que eles acreditassem que não tinham concorrentes sérios.
No que diz respeito à engenharia, a qualidade deles é amplamente superestimada, mesmo não sendo tão bem compreendida em primeiro lugar. A maioria dos sistemas é mal projetada e muitas equipes de engenharia são ineficientes, não por causa dos anos de experiência dos engenheiros ou mesmo de seu talento, mas por causa da má gestão.
Quem é quem
Outro aspecto de como a vida comercial é mais difícil para o Google é: quem realmente é o cliente?
Para a Amazon (pelo menos no sentido clássico do varejo), o cliente é claro e óbvio: a pessoa que compra algo no seu site, quer um a boa seleção, barata e rápida/entregue em sua porta. É relativamente fácil orientar toda a sua empresa em torno da questão: “mas isso é realmente bom para o cliente”? Para o Google, devido à natureza do negócio de buscas e o fato de ser sua principal fonte de receita, os incentivos são “mistos”, para dizer o mínimo. O verdadeiro cliente do Google não são os usuários, mas os anunciantes. Os usuários são simplesmente um ingrediente a ser alimentado no mecanismo de publicidade — quaisquer decisões que forem tomadas para beneficiar o usuário, são apenas da perspectiva de não irritá-los tanto a ponto de deixarem a plataforma. Quão bem a Amazon trata os funcionários de seus depósitos? Apenas o necessário para atingir 2 objetivos: não infringir as leis trabalhistas de forma muito flagrante e não agitar toda a força de trabalho empregável muito rapidamente.
De uma forma distorcida, talvez descrever a equivalência entre o Google com a Amazon seja mais ou menos assim:
Usuários do Google Search == Trabalhadores dos depósitos da Amazon
Anunciantes do Google == Compradores da Amazon
O que o Google está fazendo?
Eles não fazem bons produtos. Também não inventam muitas coisas úteis. Eles são como o garoto rico diletante, com muito dinheiro tentando coisas aleatórias diferentes sem se concentrar em uma coisa.
Conclusão
Não tenho certeza se o Google estava preparado para esta competição porque, em primeiro lugar, os termos dos negócios da Microsoft com OpenAi podem ter sido estratégicos, de difícil interpretação e, em segundo lugar, o fato de o mecanismo de busca do Google não ter experimentado iovação ou melhoria significativa desde PageRank, pelo menos da perspectiva da experiência do usuário, e não da complexidade da engenharia. Vou presentear meus descendentes com histórias de uma época em que procurei algo e encontrei pelo menos um resultado relevante entre os 20 primeiros.