O poder de computação ao alcance das pessoas começou a crescer rapidamente, aos trancos e barrancos, na virada do milênio, quando as unidades de processamento gráfico (GPUs) começaram a ser aproveitadas para cálculos não gráficos, uma tendência que se tornou cada vez mais difundida na última década.
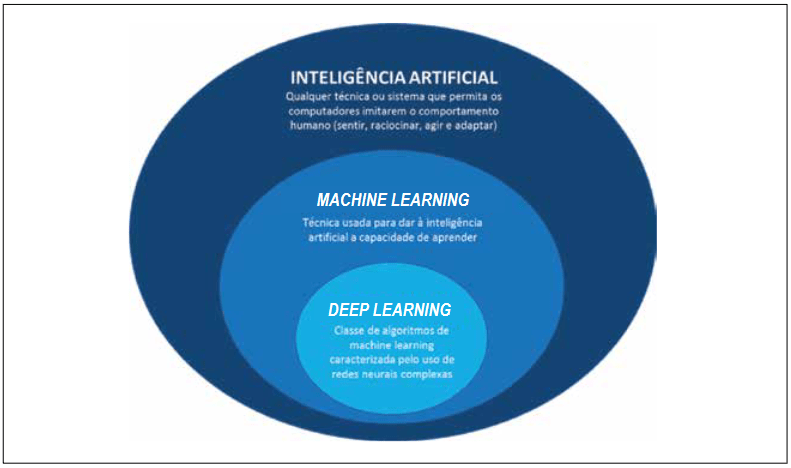
Mas as demandas da computação de “Aprendizado Profundo” [Deep Learning] têm aumentado ainda mais rápido. Essa dinâmica estimulou os engenheiros a desenvolver aceleradores de hardware voltados especificamente para o aprendizado profundo [o que se conhece popularmente como ‘Inteligência Artificial’], sendo a Unidade de Processamento de Tensor (TPU) do Google um excelente exemplo.
Aqui, descreverei resumidamente o processo geral do aprendizado de máquina. Em meio a reportagens cataclísmicas anunciando o iminente desabamento do Céu, precisamos saber um pouco sobre como os computadores realmente executam cálculos de redes neurais.
Visão geral
Quase invariavelmente, os neurônios artificiais são ‘construídos’ [na verdade eles são virtuais] usando um software especial executado em algum tipo de computador eletrônico digital.
Esse software fornece a um determinado neurônio da rede várias entradas e uma saída. O estado de cada neurônio depende da soma ponderada de suas entradas, à qual uma função não linear, chamada função de ativação, é aplicada. O resultado, a saída desse neurônio, torna-se então uma entrada para vários outros neurônios, em um processo em cascata.

Por questões de eficiência computacional, esses neurônios são agrupados em camadas, com neurônios conectados apenas a neurônios em camadas adjacentes. A vantagem de organizar as coisas dessa maneira, ao invés de permitir conexões entre quaisquer dois neurônios, é que isso permite que certos truques matemáticos de álgebra linear sejam usados para acelerar os cálculos.
Embora os cálculos de álgebra linear não sejam toda a história, eles são a parte mais exigente do aprendizado profundo em termos de computação, principalmente à medida que o tamanho das redes aumenta. Isso é verdadeiro para ambas as fases do aprendizado de máquina:
- O treinamento – processo de determinar quais pesos aplicar às entradas de cada neurônio.
- A inferência – processo deflagrado quando a rede neural está fornecendo os resultados desejados.
Matrizes
O que são esses misteriosos cálculos de álgebra linear? Na verdade eles não são tão complicados. Eles envolvem operações com matrizes, que são apenas arranjos retangulares de números – planilhas, se preferir, menos os cabeçalhos de coluna descritivos que você encontra em um arquivo Excel típico.
É bom que as coisas sejam assim, porque o hardware de um computador moderno é otimizado exatamente para operações com matriz, que sempre foram o pão com manteiga da computação de alto desempenho – muito antes de o aprendizado de máquina se tornar popular. Os cálculos matriciais relevantes para o aprendizado profundo se resumem essencialmente a um grande número de operações de multiplicação e acumulação, em que pares de números são multiplicados entre si e seus produtos somados.
Ao longo dos anos, o aprendizado profundo foi exigindo um número cada vez maior dessas operações de multiplicação e acumulação. Considere LeNet, uma rede neural pioneira, projetada para fazer classificação de imagens. Em 1998, demonstrou superar o desempenho de outras técnicas de máquina para reconhecer letras e numerais manuscritos. Mas em 2012 o AlexNet, uma rede neural que processava cerca de 1.600 vezes mais operações de multiplicação e acumulação do que o LeNet, foi capaz de reconhecer milhares de diferentes tipos de objetos em imagens.

Aliviar a pegada de CO2
Avançar do sucesso inicial do LeNet para o AlexNet exigiu quase 11 duplicações do desempenho de computação. Durante os 14 anos que se passaram, a lei de Moore ditava grande parte desse aumento. O desafio tem sido manter essa tendência agora que a lei de Moore dá sinais de que está perdendo força. A solução de sempre é simplesmente injetar mais recursos – tempo, dinheiro e energia – no problema.
Como resultado, o treinamento das grandes redes neurais tem deixado uma pegada ambiental significativa. Um estudo de 2019 descobriu, por exemplo, que o treinamento de um determinado tipo de rede neural profunda para o processamento de linguagem natural emite cinco vezes mais CO2 do que um automóvel durante toda a sua vida útil.
Os aprimoramentos nos computadores eletrônicos digitais com certeza permitiram que o aprendizado profundo florescesse. Mas isso não significa que a única maneira de realizar cálculos de redes neurais seja necessariamente através dessas máquinas. Décadas atrás, quando os computadores digitais ainda eram relativamente primitivos, os engenheiros lidavam com cálculos difíceis como esses usando computadores analógicos.
À medida que a eletrônica digital evoluiu, esses computadores analógicos foram sendo deixados de lado. Mas pode ser hora voltar a essa estratégia mais uma vez, em particular nestes tempos em que cálculos analógicos podem ser feitos oticamente de forma natural.
Nos próximas postagens vou trazer os mais recentes desenvolvimentos em fotônica aplicada ao aprendizado de máquina – em uma arquitetura analógica! Estamos, sem dúvida, vivendo tempos interessantes neste campo promissor.
Fonte de pesquisa: spectrum.ieee.org
