Nosso blog nasceu quase dois meses atrás com a proposta de trazer insights originais em língua portuguesa sobre Tecnologia/Ciência da Informação/Computação e ciências em geral. Contudo, diante da crise da COVID-19, sentimos que é nossa obrigação nos juntar às poucas vozes racionais e repercutir as marchas e contra-marchas da pesquisa científica desse patógeno, em oposição ao negacionismo desenfreado que toma conta de parte da opinião pública e de esferas governamentais. Conteúdos como este serão frequentes, enquanto durar esta emergência, que alguns classificam como “risco existencial” para a raça humana. Trazemos neste post o ponto de vista de Derek Lowe, publicado ontem por Science Magazine
* * *
Hoje temos duas notas sobre a vacina “Sputnik-V” do Instituto Gamaleya da Rússia. Nenhuma delas vai ser agradável de comentar.

Em primeiro lugar, muitos devem ter ouvido que as autoridades reguladoras brasileiras tiveram uma audiência ontem para ver se essa vacina poderia ser aprovada para uso lá. Os brasileiros recusaram, por vários motivos. Entre esses estão questionamentos referentes aos processos de fabricação e ao aumento de escala da produção, que, devo dizer, não foram muito bem documentados para esta vacina. Os leitores talvez se lembrem dos relatórios da Eslováquia dando conta de que as autoridades de lá obtiveram o que parecia ser formulações completamente diferentes da vacina, sendo que todas haviam sido enviadas no mesmo lote. Então, realmente há algum espaço para esclarecimentos sobre como esses processos são controlados. Mas a grande notícia é que a Anvisa, a agência farmacêutica brasileira, disse que cada lote da injeção Ad5 Gamaleya das quais que eles analisaram parece ainda ter adenovírus competente para replicação (grifo do tradutor). Vamos parar por um segundo para apreciar o que isso significa, para os leitores não técnicos. Os próximos parágrafos são de background.
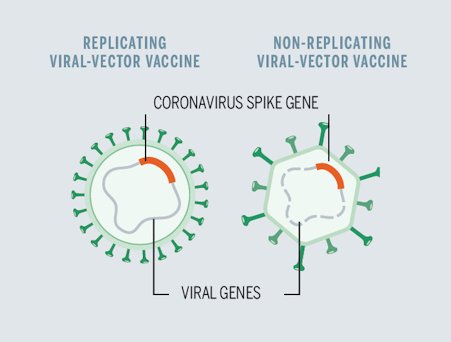
As vacinas vetoriais de adenovírus (Astra-Zeneca, Oxford, Jansen, Gamaleya, CanSino) são feitas removendo a maioria das instruções de DNA do adenovírus e inserindo no lugar o DNA para produzir antígenos de coronavírus. A Oxford usa um adenovírus de chimpanzé; a Jansen tem usado a cepa de adenovirus Ad26; CanSino tem o adenovírus Ad5 e a vacina Gamaleya é uma injeção de Ad26 seguida por uma segunda injeção de Ad5.
Embora diferentes, todas essas vacinas carregam o DNA necessário para fazer a proteína das espículas do coronavírus (algumas delas com o DNA em seu estado nativo, outras com mutações de aminoácidos estabilizadores). E todas essas cepas tiveram as partes essenciais de seu genoma original removidas para torná-las incapazes de se replicar no corpo humano (deletar um gene chamado E1 é a maneira padrão de fazer isso).
Isso significa que, quando você é injetado com essa vacina vetorial, cada partícula viral é ativada. Ela infecta uma célula em seu corpo e a instrui a fabricar a proteína da espícula (desencadeando assim a resposta imunológica quando essa proteína estranha for detectada). Basicamente, esse é todo o processo. Um vírus selvagem real fabricaria toda uma suíte de proteínas virais, que seriam agregadas a inúmeras novas partículas de vírus. Eles seriam então liberados quando a célula finalmente se enchesse de tantos vírus e se rompesse devido à sobrecarga.
Tem sido objeto de discussão, ao longo dos anos, se a imunização com adenovirus “competente para replicação”, como descrito acima, seria uma vacina eficaz, ou se estamos bem servidos com os adenovirus “incompetentes para replicação”, que sabemos são seguros e evitam o risco de uma infecção pela vacina..
Os adenovírus estão em toda parte. O que acontece quando você se infecta com uma variedade do tipo selvagem? Geralmente você pega infecções respiratórias – que variam de pessoa para pessoa. Com os adenovirus Ad5 e Ad26 essas infecções são geralmente leves, às vezes imperceptíveis, mas em algumas pessoas pode haver problemas sérios, o que é outro motivo para evitar dar às pessoas vírus com capacidade de replicação. A variedade Ad5 já infectou uma grande proporção de toda a raça humana ao longo dos milênios, o que é uma das razões pelas quais os pesquisadores preferem plataformas menos comuns, como o Ad26, ou se voltam para adenovírus de outras espécies de primatas (como a Oxford e a Astra-Zeneca). Acredita-se que, se você tiver anticorpos e células T já preparadas contra o vetor Ad5 (por exemplo), a absorção de sua carga vacinal será prejudicada, levando a uma imunização menos eficaz.
Isso também levanta questionamentos sobre a) a diminuição da eficácia nos regimes de injeção de reforço – não importando com qual cepa você comece – e b) o que acontece se você tiver que ser vacinado alguns anos mais tarde contra um patógeno completamente diferente, cuja vacina usa um vetor viral ao qual você já foi exposto. Por enquanto, parece que a ideia da injeção de reforço pode funcionar, embora a segunda injeção certamente seja mais prejudicada pela resposta imunológica. A segunda preocupação ainda é uma questão em aberto, pelo que sei. Presumivelmente, ambas seriam preocupações ainda maiores se a vacina usar DNA capaz de replicação, porque então você estaria atingindo os pacientes com um desafio viral ainda mais forte.
Ler o artigo completo na Science Magazine (in English, of course)