Noticias da IBM dão conta de que o primeiro sistema de encriptação homomórfica comercial está quase pronto para o horário nobre. É uma tecnologia realmente disruptiva que poderá tornar o Capitalismo de Vigilância uma tendência do passado. Primeiro, algum contexto. Existem três categorias gerais de criptografia. As duas clássicas são a criptografia para quando os dados estão em repouso ou armazenados, e a outra para “dados em trânsito”, que protege a confidencialidade dos dados que estão sendo transmitidos por uma rede.
A terceira é a peça que está faltando: a capacidade de computar chaves criptográficas para os dados, enquanto ainda eles ainda estão sendo processados. Uma criptografia dinâmica em tempo real, pode-se dizer.
Esta última é a chave para desbloquear todos os tipos de novos casos de uso. Isso porque, com a tecnologia comum disponível hoje, os dados têm forçosamente que ser desencriptados para que possam ser processados, o que sempre cria uma janela de vulnerabilidade. Essa janela de vulnerabilidade torna as empresas relutantes em compartilhar dados altamente sensíveis envolvendo, por exemplo, finanças ou saúde.
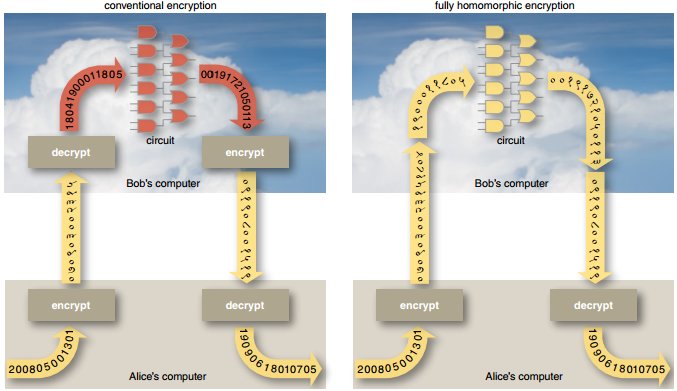
Com FHE [Fully Homomorphic Encryption – Encriptação Totalmente Homomórfica], é possível manter os dados criptografados o tempo todo, nunca expondo-os durante o processo de computação. No passado, de uma maneira ou outra tínhamos a capacidade de criptografar os dados a) em repouso e b) em trânsito. Porém, historicamente nunca tivemos a capacidade de manter os dados criptografados durante o processamento.
À esquerda, a encriptação tradicional, onde os dados precisam ser desencriptados para serem processados (em vermelho). À direita, na encriptação homomórfica, os dados são processados mesmo estando encriptados.
Com a FHE, os dados podem permanecer criptografados enquanto são usados por um aplicativo. Imagine, por exemplo, um aplicativo de navegação em um smartphone que possa dar a direção a seguir sem realmente poder ver qualquer informação ou localização pessoal do usuário.
As empresas estão potencialmente interessadas em FHE porque isso permitiria a elas aplicar “inteligência artificial” aos dados e, ao mesmo tempo, prometer honestamente aos usuários que a empresa não tem como visualizar ou acessar os dados subjacentes.
Embora o conceito de criptografia homomórfica tenha existido e sido de interesse por décadas, a FHE sempre exigiu um enorme poder de computação, o que sempre foi muito custoso para ser praticável.
Mas os pesquisadores fizeram grandes avanços nos últimos anos.
Por exemplo, em 2011 era preciso 30 minutos para processar um único bit usando FHE. Em 2015, os pesquisadores já podiam comparar dois genomas humanos inteiros usando a FHE em menos de uma hora.
A IBM vem trabalhando em FHE há mais de uma década, e está finalmente atingindo um ponto em que está pronta para começar a adotar a FHE de maneira mais ambiciosa. E aí então entra o próximo desafio: a adoção generalizada. Há atualmente poucas organizações com habilidades e conhecimentos para implementar a FHE. “
Próximos passos
Para acelerar esse desenvolvimento, a IBM Research lançou ferramentas de código aberto, para fomentar o envolvimento dos desenvolvedores, enquanto a IBM Security lançou seu primeiro serviço comercial de FHE em dezembro de 2020.
Essas iniciativas se destinam a estimular os clientes a trabalhar em protótipos e experimentar a criptografia totalmente homomórfica. São dois objetivos imediatos: Primeiro, educar os clientes sobre como construir aplicações compatíveis com FHE e, em seguida, dar a eles as ferramentas e ambientes de hospedagem adequados para executar esses tipos de aplicações. No curto prazo, a IBM prevê que as perspectivas sejam muito atraentes para indústrias altamente reguladas, como serviços financeiros e saúde. Esses serviços têm uma grande necessidade de desbloquear o valor de seus dados, mas também enfrentam pressões extremas para proteger e preservar a privacidade dos dados que estão computando.
Com o tempo, uma gama mais ampla de empresas se beneficiará da FHE. Muitos setores querem melhorar seu uso de dados, o que está se tornando um diferencial competitivo no mercado. Isso inclui o uso de FHE para ajudar a impulsionar novas formas de colaboração e monetização. À medida que isso acontece, a IBM espera que esses novos modelos de segurança estimulem uma maior adoção corporativa de suas plataformas híbridas de nuvem.
Por meu lado, desejo MERDA, à IBM em sua estréia. Estávamos realmente precisando disso. Saúde!
Este não é um blog novidadeiro ou de breaking news. Também não é um site de dicas. Meu compromisso é ter um canto na Web para discussão, em formato longo, de assuntos que não são contemplados em outras mídias e sites de língua portuguesa, mas que são importantes no debate internacional no campo da Tecnologia da Informação (de acordo com o que eu vejo). Assim, sempre haverá lugar aqui para sugestão de algumas técnicas rápidas e diretas, principalmente quando ligadas à Segurança e Privacidade Se este texto parece uma dica, que assim seja.
Alguns recursos na Internet podem ser acessados apenas a partir de clientes [*clientes são programas que rodam em seu computador local] com endereços IP específicos. Por exemplo, suponha que você queira baixar um documento da sua universidade publicado em uma revista científica. Nesse caso, normalmente você precisa se conectar ao site da revista a partir de um computador com um endereço IP que pertença à sua universidade. Se você estiver trabalhando em casa, é possível se conectar à VPN da universidade, de forma a que seu endereço IP de casa seja disfarçado como endereço IP do campus.
Contudo, nem sempre é possível usar a VPN fornecida pela sua universidade. Por exemplo, algumas VPNs requerem um software cliente especial, que pode não suportar certos sistemas operacionais, como o Linux. Existiria então alguma solução alternativa simples para VPN? A resposta é sim, se você puder estabelecer uma conexão SSH para um servidor com o endereço IP de sua universidade – por exemplo, para a estação de trabalho em execução no seu departamento. Essa conexão é chamada Túnel SSH e é implementada através de protoclos como o Socks.
Socks Proxy
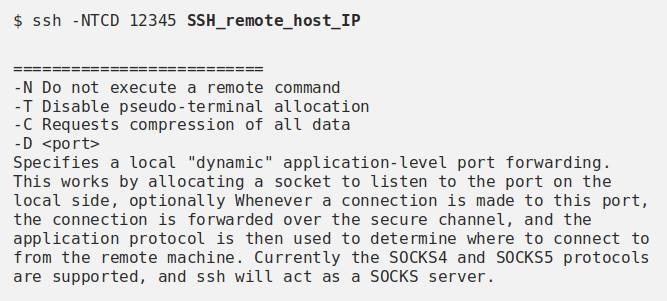
Para contornar/resolver o problema do acesso à revista científica , podemos executar o seguinte comando, que cria uma listagem do servidor Socks na porta 12345 do seu localhost.
A opção -D especifica um encaminhamento “dinâmico” de porta em nível de aplicativo local. Isso funciona alocando opcionalmente um soquete para ouvir a porta no lado local. Sempre que uma conexão for feita a esta porta, a conexão é encaminhada sobre o canal seguro e o protocolo do aplicativo é então usado para determinar onde se conectar a partir da máquina remota. Atualmente, os protocolos Socks4 e Socks5 são suportados; o SSH atuará como um servidor Socks.
Se você quiser pará-lo, basta pressionar [Control] – [C]
Firefox via Socks proxy
A próxima etapa é a configuração de proxy no seu navegador. Usarei o Firefox como exemplo. A configuração está em preferências> Configuração de rede> Configurações …
Configuração de um Socks proxy no Firefox
Depois de fazer isso, você pode logar, procurar os papers que precisa e começar a baixá-los.
Para testar essa funcionalidade VPN improvisada, pesquise “Qual é o meu IP” no duckduckgo.com (ou Google) usando o navegador com proxy. Você vai reparar que ele exibe agora o IP de ssh_remote_host_ip em vez do IP de sua máquina local.
Poucas coisas provocam um calafrio tão desconfortável quanto logar em um computador e visualizar uma mensagem dando conta de que todos os seus arquivos e dados estão bloqueados e indisponíveis para acessar. No entanto, como a sociedade depende cada vez mais da tecnologia digital, esse é um cenário cada vez mais comum. Ransomware, uma aplicação que criptografa os dados para que os cibercriminosos possam extrair um pagamento pelo seu retorno seguro, tornou-se cada vez mais comum – e caro. Um relatório de 2019 da empresa de segurança Emisoft projetou o custo anual de ransomware em mais de US $ 7,5 bilhões, apenas nos EUA.
Uma pop up de ransomware
“Indivíduos, empresas, hospitais, universidades e governo, todos já caíram vítimas de ataques”, diz Chris Hinkley, chefe da equipe de pesquisa da unidade de resistência a ameaças (TRU) da firma de segurança Armour. Em um cenário de pior caso, os resgates exigidos podem ser da ordem de dezenas de milhões de dólares, capazes de fechar inteiramente as operações de uma organização. Ransomware já forçou hospitais a redirecionar pacientes a outras instalações, interrompeu serviços de emergência e destruiu negócios.
O problema só vai piorar, apesar do desenvolvimento de novas e mais avançadas maneiras de combatê-lo, incluindo o uso de análise comportamental e inteligência artificial. “As Cybergangs usam diferentes algoritmos criptográficos e distribuem software notavelmente sofisticado e difícil de detectar”, diz Hinkley. “Hoje, quase não há barreiras para a entrada no negócio de ramsonware, e o dano infligido é enorme”.
É obrigatório pela política das empresas. É uma boa prática recomendada por todos. E não é novidade para praticamente nenhum de nós: as senhas devem ser longas, variadas no uso de caracteres (maiúsculas, minúsculas, números, caracteres especiais) e não baseadas em palavras de dicionário. Bastante simples, certo? Mas deixe-me ir um pouco além e fazer uma pergunta não tão simples:
O que é mais forte, uma senha aleatória de 8 caracteres que potencialmente usa todo o conjunto de caracteres ASCII (maiúsculas, minúsculas, números, caracteres especiais (incluindo um espaço)) ou uma senha aleatória de 10 caracteres que usa apenas letras maiúsculas e minúsculas?
Desconsidere por um momento a sua situação particular; essa não é a questão.
Como fazer uma comparação exata entre as duas senhas? Elas diferem de muitas maneiras. Na literatura especializada, um argumento afirma que uma senha mais longa, mesmo usando um conjunto de caracteres menor, é mais forte. Outro argumento pode afirmar que uma senha mais curta tem potencial de ser mais forte quando extraída de uma lista maior de caracteres potenciais. Um argumento é pela extensão, o outro é pela complexidade. Então, qual é o mais resistente a um ataque?
Esta questão se aplica diretamente a discussões de políticas dentro de uma organização. Como podemos avaliar a solidez de qualquer política de senhas proposta? Seus requisitos de política são arbitrários ou baseados em algum tipo de medida quantitativa? É simples dizer, “torne as senhas suficientemente longas, complexas e não baseadas em palavras do dicionário”, mas seria possivel quantificar o que é “suficiente” para uma determinada situação? Os cenários variam. Todos nós temos necessidades diferentes e os vários sistemas têm vários níveis de suporte de senha. Ainda cabem outras perguntas: existe um ponto de diminuição dos retornos sobre a complexidade da senha? Em que ponto elas se tornam tão longas e complexas que se tornam praticamente inutilizáveis? Existe uma resposta.
A resposta (ou parte dela, pelo menos) a essas perguntas está na quantidade de entropia informacional que a senha carrega. Volumes e mais volumes de discussão já foram impressos sobre os conceitos de entropia de informação e seus usos na comunicação, mas para nossos propósitos vamos apenas dizer que, no final, o conceito de entropia de senha nos fornece uma maneira de comparar empiricamente a força potencial de uma senha com base em seu comprimento e no universo de caracteres que ela pode conter. Para explicar o porquê, deixe-me começar com uma demonstração simples.
Selecione aleatoriamente uma letra de A – Z.
Agora vou tentar adivinhar. Quantas suposições você acha que vou precisar? Eu poderia adivinhar em apenas uma tentativa? Sim. Mas também posso precisar de 25 palpites, certo? Se eu simplesmente começasse a adivinhar aleatoriamente, meu sucesso também seria aleatório. Mas se eu aplicar os conceitos básicos da teoria da informação para a execução da tarefa, algo muito interessante acontece. Não importa qual letra você selecione, sempre precisarei de apenas quatro (4), e nunca mais do que cinco (5) perguntas para adivinhar sua letra. Em contraste, se eu fosse adivinhar ao acaso, precisaria, em média, de 13 tentativas para adivinhar sua letra. Mas quando conceitos de entropia de informação são aplicados, o número de perguntas / suposições cai para consistentes 4 ou 5. O motivo é bastante simples: eu não “adivinho” as letras; eu as elimino. Suponhamos que a letra que você selecionou seja “D”. Aqui está como minha cadeia de questionamento (o algoritmo) se comporta:
Pergunta 1: sua letra está entre N e Z? Resposta: Não.
Se sim, sua letra está entre N-Z.
Se não, sua letra é entre A-M.
Pergunta 2: sua letra está entre A e G? Resposta: sim.
Se sim, sua letra é entre A-G.
Se não, sua letra é entre H-M.
Pergunta 3: sua letra está entre A-D? Resposta: sim.
Se sim, sua letra é entre A-D.
Se não, sua letra é entre E-G.
Pergunta 4: sua letra está entre A-B? Resposta: Não.
Se sim, sua letra é entre A-B.
Se não, sua letra é entre C-D.
Pergunta 5: A sua letra é C? Resposta: Não.
Se sim, sua letra é C.
Se não, sua letra é D.
Resultado: sua letra é D. Estimativas: 5
Vamos fazer de novo. Desta vez, vamos supor que você escolheu aleatoriamente a letra “H”.
Pergunta 1: sua letra está entre N e Z? Resposta: Não.
Se sim, sua letra está entre N-Z.
Se não, sua letra é entre A-M.
Pergunta 2: sua letra está entre A e G? Resposta: Não.
Se sim, sua letra é entre A-G.
Se não, sua letra é entre H-M.
Pergunta 3: sua letra está entre H-I? Resposta: sim.
Se sim, sua letra é entre H-I.
Se não, sua letra é entre J-K.
Pergunta 4: A sua letra é H? Resposta: sim.
Se sim, sua letra é H.
Se não, sua letra é entre I-J.
Resultado: sua letra é H. Estimativas: 4
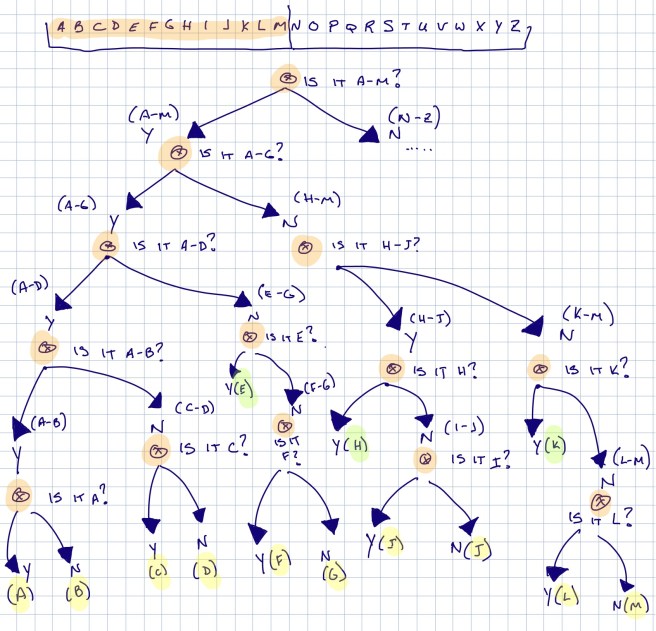
A imagem abaixo mostra a árvore de decisão usada. Cada ‘x’ laranja é uma pergunta. As letras destacadas em verde serão identificados em 4 questões e as letras destacadas em amarelo serão identificadas em 5. A árvore de decisão na imagem mostra apenas a metade esquerda do alfabeto (A-M). Você pode replicar o lado direito do alfabeto (N-Z) em uma árvore semelhante. Se você examinar o número de questões para todas as 26 letras do alfabeto, verá que seis (6) das letras podem ser identificadas em quatro (4) questões, enquanto as vinte (20) letras restantes serão identificadas em cinco (5) questões.
Árvore de decisão do problema
Então, se fôssemos jogar esse jogo de adivinhação indefinidamente, quantas perguntas, em média, eu precisaria para adivinhar a letra escolhida?
Para calcular o número médio de perguntas que terei que fazer para determinar sua letra, tenho que saber qual será a probabilidade de uma letra ser selecionada. Para este exemplo, estou supondo que cada uma das 26 letras do alfabeto tem uma chance estatisticamente igual de ser selecionada (mais sobre as nuances dessa suposição posteriormente). Um cálculo rápido mostra que 1/26 = 0,0384. Convertendo isso em porcentagem saberemos que cada letra tem 3,84% de chance de ser a letra selecionada aleatoriamente.
Como aqui não fugimos da matemática e valentemente a enfrentamos, há uma equação para essa pergunta. Vejamos:
Esta equação calcula H, que é o símbolo usado para entropia. Para o nosso alfabeto, a equação ficaria assim:
E agora temos a resposta: terei que fazer uma MÉDIA de 4.7004 perguntas para determinar a letra selecionada aleatoriamente no alfabeto.
Mais formalmente, diríamos que existem 4.7004 ‘bits de entropia’.
Se você aplicar esta matemática a um único caractere selecionado aleatoriamente a partir dos diferentes conjuntos de caracteres que existem, você obterá o seguinte:
Binário (0, 1) -> H = 1 (1 bit de entropia)
Terei que fazer uma pergunta para determinar se o valor selecionado aleatoriamente é 1 ou 0.
Decimal (0-9) -> H = 3,32193 (3,2193 bits de entropia)
Terei que fazer uma média de 3,32193 perguntas para determinar o número selecionado aleatoriamente (0-9).
Hexadecimal (0-9, A-F) -> H = 4.000
Terei que fazer quatro (4) perguntas para determinar seu valor (a-f, 0-9)
Alfabeto maiúsculo e minúsculo (a-z, A-Z) -> H = 5,7004
Terei que fazer uma média de 5.7004 perguntas para determinar sua letra selecionada aleatoriamente (a-z, A-Z).
Todos os caracteres ASCII imprimíveis (incluindo espaço) -> H = 6,5699
Terei que fazer uma média de 6.5699 perguntas para determinar seu valor selecionado aleatoriamente.
Vamos desenvolver isso um pouco mais. Os números acima são para uma ÚNICA letra selecionada aleatoriamente. E se eu pedisse para você escolher duas (2) letras aleatoriamente? Agora, adivinhando uma letra de cada vez, quantas tentativas, em média, eu precisaria para descobrir as duas? A resposta é aditiva, o que significa que você só precisa adicionar a entropia para cada letra. Se a entropia de uma única letra minúscula é 4,7004, a entropia de duas letras selecionadas aleatoriamente é 4,7004 + 4,7004. Isso é 9.4008 perguntas para determinar as duas letras (assumindo a-z, como em nosso exemplo original). Se eu pedisse a você para selecionar uma seqüência de dez (10) caracteres aleatórios, seria necessária uma média de 47,004 perguntas (4,7004 * 10) para adivinhar todos eles.
Tudo bom, tudo bem, mas isso presume que sou capaz de adivinhar apenas um valor de cada vez. Se você escolhesse aleatoriamente 10 letras do alfabeto, eu poderia adivinhar a primeira em cerca de 4,7 tentativas, a segunda em 4,7 tentativas, a terceira em 4,7 tentativas e assim por diante. Mas no mundo real, não é assim que se adivinha senhas (um caractere por vez). Um invasor terá que adivinhar corretamente todos os dez valores de uma só vez para determinar as letras selecionadas aleatoriamente. Isso é, obviamente, uma coisa muito mais difícil de fazer. Mas quão difícil? Para descobrir, vamos voltar à pergunta original que fiz:
O que é mais forte, uma senha aleatória de 8 caracteres que potencialmente usa todo o conjunto de caracteres ASCII (maiúsculas, minúsculas, números, caracteres especiais ( incluindo um espaço)) ou uma senha aleatória de 10 caracteres que usa apenas letras maiúsculas e minúsculas?
Bem, se seu conjunto de caracteres tiver 26 letras minúsculas (az), 26 caracteres maiúsculos (AZ), e sua senha tiver 10 caracteres, haverá 5210 combinações possíveis de letras (26 caracteres (az) + 26 caracteres ( AZ) = 52 caracteres). Esse é um número grande. 144.555.105.949, 057.000 (144,5 quatrilhões), para ser exato ..
Então, para resumir esses valores:
Número de caracteres no conjunto de caracteres (a-z, A-Z): 52
Número de caracteres na senha: 10
Número total de combinações possíveis de sequências de 10 caracteres: = 52^10 = 144.555.105.949.057.000
É aqui que a magia entra em ação:
Qual é a entropia de um único caractere no conjunto completo de caracteres alfa (a-z, A-Z)? Já determinamos que é 5.7004.
Qual é o tamanho da sequência de caracteres selecionada aleatoriamente? 10 caracteres.
Qual é a entropia de uma string de 10 caracteres usando o conjunto de caracteres alfa maiúsculos / minúsculos? 5,7004 * 10 = 57,004
O que é 257,004 ? São 144.555.105.949.057.000 !!! Caramba!!! É o mesmo número que 5210!!!
Sua string de 10 caracteres, maiúsculas / minúsculas (senha) tem 57,004 bits de entropia. Supondo que um invasor acertaria a string em 50% de todas as suposições possíveis, estimamos que ele / ela terá que fazer 72.277.552.974.528.300 suposições (sim, em média) antes de adivinhar sua string de 10 caracteres.
Para dizer isso de forma mais significativa: Uma senha de 10 caracteres maiúsculos / minúsculos tem 57,004 bits de entropia.
Então, quantos bits de entropia nossa senha concorrente tem? É uma senha de 8 caracteres que utiliza o conjunto completo de caracteres ASCII (incluindo um espaço). Se você voltar ao meio desta postagem, verá que um caractere selecionado aleatoriamente do conjunto completo de caracteres ASCII tem 6,5699 bits de entropia. Isso significa que uma senha de 8 caracteres selecionada aleatoriamente nesse intervalo terá 52.559 (8 * 6.5699) bits de entropia.
Para resumir os valores das senhas de 8 caracteres:
Número de caracteres no conjunto de caracteres (a-z, A-Z, 0-9, todos os caracteres especiais, incluindo espaço): 95 Número de caracteres na senha: 8 Número total de combinações possíveis de sequências de 8 caracteres: = 958= 6.634.204.312.890.620 (6,63 quatrilhões)
E vemos que a magia é real:
Qual é a entropia de um único caractere no conjunto de caracteres ASCII completo (incluindo espaço)? Já determinamos que é 6,5699.
Qual é o tamanho da sequência de caracteres selecionada aleatoriamente? 8 caracteres.
Qual é a entropia de uma string de 8 caracteres usando o conjunto de caracteres alfa maiúsculos e minúsculos? 6,5699 * 8 = 52,559
O que é 252.559? É 6.634.204.312.890.620 !!! Caramba, de novo !!! É o mesmo número que 958!!!
Nossa senha de 10 caracteres em maiúsculas / minúsculas tem 57,004 bits de entropia.
Nossa senha de conjunto de caracteres ASCII completa de 8 caracteres tem 52.559 bits de entropia.
Quanto mais bits de entropia uma senha possui, mais forte ela é. E, isso é importante, pois um único bit de entropia representa um aumento EXPONENCIAL na resistencia da senha. Há uma grande diferença entre a força de nossas duas senhas (4,445 ordens de magnitude); isso não é trivial. É algo enorme.
Então, por que usar a entropia como a expressão da força (resistência) da senha? Os gurus da teoria da informação podem certamente dar palestras por dias sobre essas questões, mas há uma resposta simples: os humanos são realmente péssimos para lidar com grandes números. Basta ver como lembramos números de telefone, endereços IP, números de cartão de crédito e números de CPF para evidenciar nossa repulsa por grandes números. Se houver uma maneira de simplificar a expressão de um valor, sempre optaremos por ela. Afinal, o que é mais fácil de dizer e entender ?:
Minha senha tem 5210 possibilidades vs 958 possibilidades. ou; Minha senha tem 57,004 bits de entropia vs 52,559 bits de entropia.
Com certeza você achará esta última forma mais agradável.
Quanto maior o número de bits de entropia de uma senha, mais forte ela tem o potencial de ser. Eu uso a palavra “potencial” aqui porque há muitas nuances nessa discussão que podem tornar esses números um reflexo impreciso da força da senha. A principal delas é o fato de que a maioria das senhas são geradas por humanos, não por geradores de números aleatórios. Os humanos são muito, muito ruins em gerar aleatoriedade. Somos terrivelmente péssimos nisso. Isso significa que a equação usada acima, que assume que cada caracter tem uma probabilidade igual de ser selecionado, não é tão precisa quando é uma pessoa que está escolhendo as letras. Quando invasores, com auxilio do poder de computação, começam a fazer suposições realmente boas sobre como as senhas estão sendo criadas (permitindo que eles excluam certos valores, por exemplo), a entropia pode cair muito rapidamente. Isso é não é bom.
É frequente acontecer que um dos sistemas de uma organização pode suportar o uso do conjunto de caracteres ASCII completo ao definir senhas, enquanto outro pode suportar apenas senhas alfanuméricas. Quantos bits de entropia uma senha deve ter para ser adequadamente segura? Quão longa uma senha alfanumérica deve ser para ser tão forte quanto uma senha que usa o conjunto completo de caracteres? Essas são perguntas muito importantes, especialmente quando se trata de uma política corporativa de senhas. Especificar o comprimento da senha pode ser uma medida inadequada de resistencia; especificar requisitos de entropia de senha tem o potencial de ser uma expressão muito mais consistente dos requisitos de segurança. Não tenho uma citação aqui, mas muitas organizações gostam de ter 80 bits de entropia ou mais. Nos dias de hoje, isso é muita entropia. Cheque novamente em alguns anos e certamente veremos que essa declaração se tornou falsa (pela Lei de Moore).
Uma observação final: há muitas variáveis que devem ser discutidas ao explorar o assunto “senhas”. Complexidade, comprimento e entropia são todos ótimos itens para se entender, mas outros fatores podem ser tão importantes quanto. Por exemplo, quais mecanismos subjacentes suas senhas empregam? Qual algoritmo de hash? As senhas são “salgadas”? Há algum tipo de mecanismo de compatibilidade com versões anteriores habilitado (NTLM, etc.)? Essas coisas influenciam a discussão tanto quanto a entropia e podem ter um grande impacto em quanto esforço um invasor terá de fazer para adivinhar a senha. É um grande tópico, digno de muita reflexão e reflexão cuidadosa. A entropia é um ótimo lugar para começar… mas não é a única coisa a se considerar.
O meu computador de sonho é muito simples. Tão simples que talvez seja impossível de possuir em 2021. Eu quero um computador que possa ser completamente autônomo quando eu quero que ele o seja, mas que também possa ser usado para comunicação segura com qualquer pessoa no planeta sem que eu seja observado por terceiros. Eu não quero ser espionado pelas grandes companhias de Internet. Eu não quero que as agências-de-três-letras dos EUA interceptem minhas conversas ou mesmo meus metadados.
Eu quero completa autonomia e privacidade sem ter que recorrer às soluções alternativas (anti-vírus, bloqueador de anúncios, etc, etc) que foram inventadas para “recuperar” um pouco do controle que eu deveria ter tido de maneira natural e assegurada em primeiro lugar. Em outras palavras, quero um computador que eu possua completamente. Eu quero um computador que faça o que eu quero que ele faça, não um que tenha objetivos nefários escondidos em seus circuitos, programados nele na fábrica.
E ainda mais, eu quero ter essas capacidades, independentemente do que legisladores e autoridades façam com a Internet para evitar que eu as tenha. Eu não quero ser dependente dos caprichos de um governo, ou da boa vontade de uma corporação gigante. Talvez eu esteja procurando por algo como o computador CP-300 que eu tinha no início dos anos 80, mas 10.000 vezes mais rápido, com uma solução de privacidade embutida, para que eu tenha total privacidade on-line e a capacidade de executar software moderno sem me preocupar com spyware.
A realidade…
Em lugar de meu computador de sonho, eu tenho um computador que é projetado em grande parte para maximizar os lucros da indústria de computadores. Exceto por um punhado de modelos muito avançados, com preços que a maioria das pessoas não pode comprar, nossos computadores são, cada vez mais, projetados para serem pequenas plataformas de publicidade, bem como veículos para maximizar as receitas de seus verdadeiros proprietários: coletores de dados on-line, anunciantes e empresas de “nuvem”.
Nossos computadores têm inúmeros componentes de hardware e software (backdoors) que são projetados para permitir que governos e corporações nos espionem e nos sigam pela internet. Tudo que podemos fazer é confiar em algoritmos de criptografia que são projetados com falhas sutis que podem levar anos, se não décadas, para vir à luz.
Mesmo os algoritmos de criptografia de código aberto, que alguns reivindicam estar acima de reprovação, são repetidamente denunciados por terem grandes falhas, e mesmo os protocolos de correção para essas falhas têm suas próprias falhas.
Isso tudo muitas vezes parece ser intencional, porque sabemos que os governos não suportam, por um único instante, que qualquer pessoa, em qualquer lugar, possa ouvir, dizer ou ver qualquer coisa que eles mesmos não têm conhecimento. Os governos parecem ficar universalmente aterrorizados com a menor possibilidade de que duas pessoas no mundo possam ter uma conversa privada.
Assim, eles fazem tudo o que podem para assediar as empresas de software e fabricantes de computadores, induzindo-as a criar “portas de fundos” e falhas intencionais que podem ser exploradas para tirar a nossa privacidade e nos impedir de falar livremente. E quando isso não funciona, eles passam leis que visam destruir a liberdade de expressão on-line, enquanto acenam suas bandeiras proclamando a sorte de estarmos vivendo sob seus governos.
Haverá um fim para este estado de coisas? Eu terei um dia o computador dos meus sonhos?