Programador, Desenvolvedor, Analista de Sistemas, trabalhando (e estudando) na intersecção da Análise/Ciência de Dados, Aprendizado de Máquina e Segurança.
A dependência cada vez maior do software dentro do desenvolvimento automotivo, juntamente com a crescente complexidade desse software, coloca mais pressão do que nunca sobre os processos de desenvolvimento. Hoje em dia, é preciso mais de 100 milhões de linhas de código para construir um único carro de passageiros. Quando atingirmos o ponto em que os carros se tornarão completamente autônomos, o volume e a complexidade do código atingirão alturas ainda maiores.
Os veículos autônomos da próxima geração provocarão, é certo, um aumento na dependência do software. Mas até mesmo os veículos “padrão” de agora incorporam uma variedade de sistemas de software, muitas vezes conectados à Internet das Coisas e exigindo atualizações regulares.
É por isso que as arquiteturas abertas tornaram-se tão importantes nos últimos anos, ajudando a padronizar elementos de software, tornando-o “à prova de futuro” tanto quanto possível, para ajudar a gerenciar a crescente complexidade, permitir que equipes de software colaborem melhor, assegurando a conformidade dos processos, tudo isso sem sacrificar o tempo para o atendimento ao mercado. Adicionalmente, padrões de codificação e diretrizes são necessários para garantir que os componentes de software sejam confiáveis, fáceis de manter e, acima de tudo, seguros.
MISRA e AutoSAR
C e C++ são as linguagens de programação dominantes no mundo automotivo. O MISRA C, o MISRA C++ e as diretrizes de codificação AutoSAR C++ são os principais padrões de codificação. O MISRA é uma colaboração entre fabricantes de veículos, fornecedores de componentes e consultorias de engenharia. Formado no final dos anos 90, promove as melhores práticas no desenvolvimento de sistemas eletrônicos relacionados à segurança para veículos rodoviários. Seus padrões de codificação também são usados em outras indústrias onde a segurança, a qualidade e a confiabilidade são uma prioridade, incluindo ferrovias, a industria aeroespacial, telecomunicações, dispositivos médicos e defesa. Hoje, o MISRA é aceito em todo o mundo para o desenvolvimento de software de missão crítica, nas linguagens C e C++.
O MISRA por enquanto pode ser o mais estabelecido e mais amplamente utilizado dos padrões, mas o uso crescente da moderna C++ está estimulando rapidamente a adoção das diretrizes da AutoSAR. AutoSAR é uma parceria entre mais de 180 empresas envolvidas na indústria automotiva, com o objetivo de padronizar arquiteturas abertas para software automotivo e desenvolvimento de sistemas incorporados. AutoSAR é considerado por muitos ser a plataforma de facto para o futuro design automotivo.
A plataforma adaptativa da AutoSAR atende as necessidades dos veículos conectados e da condução autônoma. Ela é projetada para tecnologias como microprocessadores de 32 e 64 bits de alta potência com memória externa, processamento paralelo e comunicações de alta largura de banda. As diretrizes de codificação AutoSAR C++ foram criadas para apoiar o desenvolvimento de componentes da plataforma adaptativa que utiliza a linguagem C++ moderna. Tais componentes devem cumprir os requisitos de segurança funcional rigorosos da ISO 26262.
A ISO 26262 é o padrão internacional para a segurança funcional dos sistemas elétricos e eletrônicos automotivos (E/E). O padrão cobre todo o ciclo de vida de produção. Um dos seus principais princípios é analisar os riscos no início do processo de desenvolvimento, estabelecer os requisitos de segurança apropriados e cumprir esses requisitos durante o desenvolvimento.
Dentro do padrão, a Parte 6 aborda especificamente o desenvolvimento de software, colocando requisitos particularmente sobre o início do desenvolvimento de software, sobre o projeto arquitetônico de software e design e sobre a implementação da unidade de software. Ela padroniza os métodos de desenvolvimento que devem ser aplicados para atingir um nível de integridade de segurança automotiva específico (ASIL).
O uso de um padrão de codificação aceito universalmente, como o MISRA ou a AutoSAR, facilita a tarefa de garantir que o software da indústria esteja em conformidade com a ISO 26262.
Aderindo aos padrões de codificação
O que o Misra e o AutoSAR têm em comum é que eles dão aos desenvolvedores uma estrutura dentro da qual eles podem desenvolver software “seguro”. No entanto, os padrões não fazem o trabalho do desenvolvedor, e desenvolver sistemas seguros seguros em C++ é um desafio que não deve ser subestimado. Embora seja uma linguagem de programação que dá aos desenvolvedores mais escopo para a inovação, a flexibilidade inerente à C++ também significa que uma tomada de decisão mais cuidadosa é necessária (por exemplo, sobre como lidar com a memória dinâmica). Em outras palavras, o C++ simplifica a programação de sistemas complexos, mas necessita de mais desenvolvedores.
Padrões de codificação ajudam, mas ainda podem ser um desafio para até mesmo o desenvolvedor mais experiente: lidar com áreas de ambiguidade ou interpretação requer experiência e experiência considerável. Selecionar as ferramentas e técnicas corretas são um papel importante a ser desempenhado.
Inspeção de código contínua
Outra boa prática é garantir que cada linha de código seja cuidadosamente inspecionada em todo o processo de desenvolvimento, para garantir que ela seja segura e confiável. Para evitar que isso seja um processo manual, os desenvolvedores usam cada vez mais ferramentas automatizadas, como analisadores estáticos para verificar o código. Como resultado, quaisquer problemas – como desvio a partir de um padrão de codificação, excesso de complexidade ou um bug de DataFlow de disco rígido – podem ser detectados no início do processo. Essa abordagem também reduz a carga subsequente nos processos de teste que tradicionalmente ocorreriam mais tarde no processo de desenvolvimento. É representativo da tendência ‘esquerda volver’, onde os desenvolvedores assumem alguns dos trabalhos que anteriormente eram realizados por testadores ou técnicos de garantia de qualidade.
Normas ajudam estabelecer uma ‘única fonte de verdade transparente’ onde cada versão de cada ativo digital associada a um projeto também suporte melhor a adesão aos requisitos de conformidade. Isso fornece uma visão em tempo real e histórica de quem fez o que, quando, onde e como. No mundo automotivo, isso pode incluir informações relacionadas ao software e hardware, como documentação, código e outros artefatos de design, entre os colaboradores internos e externos. No desenvolvimento de software automotivo, há tipicamente muitos tipos de ferramentas, arquivos, plataformas e diferentes equipes que contribuem para um projeto, por isso é essencial que a única fonte de verdade apóie essa diversidade.
Muitas equipes de desenvolvimento automotivo estão descobrindo que precisam de um sistema de controle de versão de alto desempenho que possa ser dimensionado para suportar o tamanho crescente de sua base de código, ao mesmo tempo apoiando adequadamente outros tipos de ativos binários. Elas também precisam de uma ferramenta de análise de código estática para se integrarem a este sistema de controle e para gerenciar violações do padrão de codificação à medida que seu código evolui.
Finalmente, como a tecnologia, ferramentas e processos que sustentam o desenvolvimento automotivo continuam a evoluir (como também novos problemas são introduzidos), é importante continuar monitorando a situação e permanecer com a cabeça aberta a novas ideias. Neste mercado de ritmo acelerado, uma coisa das quais podemos ter certeza é a mudança.
Kobe – O supercomputador Fugaku, do Japão, o mais rápido do mundo em termos de velocidade de processamento, entrou em pleno funcionamento na última terça-feira (9/3), bem antes do que havia sido inicialmente agendado, na esperança de que possa ser usado para pesquisa relacionada ao coronavírus.
O supercomputador, cujo nome é uma alusão à palavra alternativa para o Monte Fuji, tornou-se parcialmente operacional em abril do ano passado para gerar visualizações de como as gotículas que carregam o vírus se espalham na boca e para ajudar a explorar possíveis tratamentos para a Covid-19.
“Espero que Fugaku seja estimado pelo povo, à medida que ele pode fazer o que seu antecessor, K, não podia, incluindo inteligência artificial (aplicativos) e grande capacidade de análise de dados”, disse Hiroshi Matsumoto, presidente do Instituto de Pesquisa de Riken, que desenvolveu a máquina, em uma cerimônia realizada no Centro de Riken para a Ciência Computacional em Kobe, onde está instalado.
Fugaku, que pode executar mais de 442 quatrilhões de cálculos por segundo, foi originalmente agendado para começar a operar totalmente no ano fiscal que começa em abril.
É obrigatório pela política das empresas. É uma boa prática recomendada por todos. E não é novidade para praticamente nenhum de nós: as senhas devem ser longas, variadas no uso de caracteres (maiúsculas, minúsculas, números, caracteres especiais) e não baseadas em palavras de dicionário. Bastante simples, certo? Mas deixe-me ir um pouco além e fazer uma pergunta não tão simples:
O que é mais forte, uma senha aleatória de 8 caracteres que potencialmente usa todo o conjunto de caracteres ASCII (maiúsculas, minúsculas, números, caracteres especiais (incluindo um espaço)) ou uma senha aleatória de 10 caracteres que usa apenas letras maiúsculas e minúsculas?
Desconsidere por um momento a sua situação particular; essa não é a questão.
Como fazer uma comparação exata entre as duas senhas? Elas diferem de muitas maneiras. Na literatura especializada, um argumento afirma que uma senha mais longa, mesmo usando um conjunto de caracteres menor, é mais forte. Outro argumento pode afirmar que uma senha mais curta tem potencial de ser mais forte quando extraída de uma lista maior de caracteres potenciais. Um argumento é pela extensão, o outro é pela complexidade. Então, qual é o mais resistente a um ataque?
Esta questão se aplica diretamente a discussões de políticas dentro de uma organização. Como podemos avaliar a solidez de qualquer política de senhas proposta? Seus requisitos de política são arbitrários ou baseados em algum tipo de medida quantitativa? É simples dizer, “torne as senhas suficientemente longas, complexas e não baseadas em palavras do dicionário”, mas seria possivel quantificar o que é “suficiente” para uma determinada situação? Os cenários variam. Todos nós temos necessidades diferentes e os vários sistemas têm vários níveis de suporte de senha. Ainda cabem outras perguntas: existe um ponto de diminuição dos retornos sobre a complexidade da senha? Em que ponto elas se tornam tão longas e complexas que se tornam praticamente inutilizáveis? Existe uma resposta.
A resposta (ou parte dela, pelo menos) a essas perguntas está na quantidade de entropia informacional que a senha carrega. Volumes e mais volumes de discussão já foram impressos sobre os conceitos de entropia de informação e seus usos na comunicação, mas para nossos propósitos vamos apenas dizer que, no final, o conceito de entropia de senha nos fornece uma maneira de comparar empiricamente a força potencial de uma senha com base em seu comprimento e no universo de caracteres que ela pode conter. Para explicar o porquê, deixe-me começar com uma demonstração simples.
Selecione aleatoriamente uma letra de A – Z.
Agora vou tentar adivinhar. Quantas suposições você acha que vou precisar? Eu poderia adivinhar em apenas uma tentativa? Sim. Mas também posso precisar de 25 palpites, certo? Se eu simplesmente começasse a adivinhar aleatoriamente, meu sucesso também seria aleatório. Mas se eu aplicar os conceitos básicos da teoria da informação para a execução da tarefa, algo muito interessante acontece. Não importa qual letra você selecione, sempre precisarei de apenas quatro (4), e nunca mais do que cinco (5) perguntas para adivinhar sua letra. Em contraste, se eu fosse adivinhar ao acaso, precisaria, em média, de 13 tentativas para adivinhar sua letra. Mas quando conceitos de entropia de informação são aplicados, o número de perguntas / suposições cai para consistentes 4 ou 5. O motivo é bastante simples: eu não “adivinho” as letras; eu as elimino. Suponhamos que a letra que você selecionou seja “D”. Aqui está como minha cadeia de questionamento (o algoritmo) se comporta:
Pergunta 1: sua letra está entre N e Z? Resposta: Não.
Se sim, sua letra está entre N-Z.
Se não, sua letra é entre A-M.
Pergunta 2: sua letra está entre A e G? Resposta: sim.
Se sim, sua letra é entre A-G.
Se não, sua letra é entre H-M.
Pergunta 3: sua letra está entre A-D? Resposta: sim.
Se sim, sua letra é entre A-D.
Se não, sua letra é entre E-G.
Pergunta 4: sua letra está entre A-B? Resposta: Não.
Se sim, sua letra é entre A-B.
Se não, sua letra é entre C-D.
Pergunta 5: A sua letra é C? Resposta: Não.
Se sim, sua letra é C.
Se não, sua letra é D.
Resultado: sua letra é D. Estimativas: 5
Vamos fazer de novo. Desta vez, vamos supor que você escolheu aleatoriamente a letra “H”.
Pergunta 1: sua letra está entre N e Z? Resposta: Não.
Se sim, sua letra está entre N-Z.
Se não, sua letra é entre A-M.
Pergunta 2: sua letra está entre A e G? Resposta: Não.
Se sim, sua letra é entre A-G.
Se não, sua letra é entre H-M.
Pergunta 3: sua letra está entre H-I? Resposta: sim.
Se sim, sua letra é entre H-I.
Se não, sua letra é entre J-K.
Pergunta 4: A sua letra é H? Resposta: sim.
Se sim, sua letra é H.
Se não, sua letra é entre I-J.
Resultado: sua letra é H. Estimativas: 4
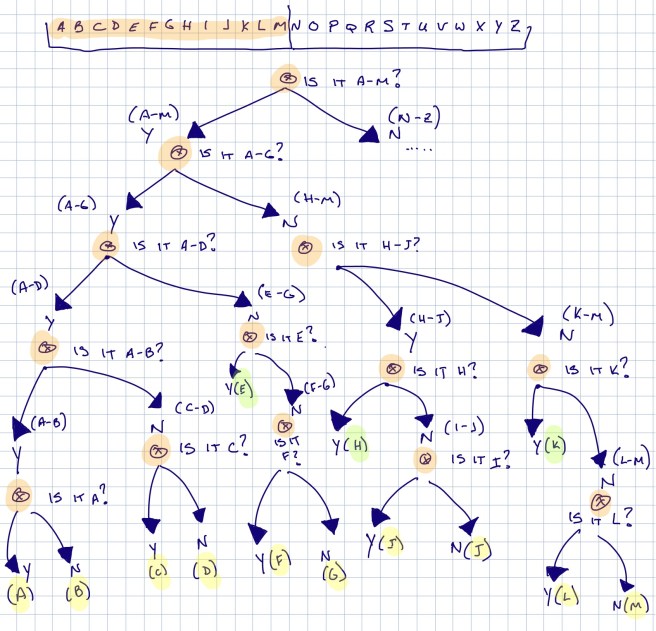
A imagem abaixo mostra a árvore de decisão usada. Cada ‘x’ laranja é uma pergunta. As letras destacadas em verde serão identificados em 4 questões e as letras destacadas em amarelo serão identificadas em 5. A árvore de decisão na imagem mostra apenas a metade esquerda do alfabeto (A-M). Você pode replicar o lado direito do alfabeto (N-Z) em uma árvore semelhante. Se você examinar o número de questões para todas as 26 letras do alfabeto, verá que seis (6) das letras podem ser identificadas em quatro (4) questões, enquanto as vinte (20) letras restantes serão identificadas em cinco (5) questões.
Árvore de decisão do problema
Então, se fôssemos jogar esse jogo de adivinhação indefinidamente, quantas perguntas, em média, eu precisaria para adivinhar a letra escolhida?
Para calcular o número médio de perguntas que terei que fazer para determinar sua letra, tenho que saber qual será a probabilidade de uma letra ser selecionada. Para este exemplo, estou supondo que cada uma das 26 letras do alfabeto tem uma chance estatisticamente igual de ser selecionada (mais sobre as nuances dessa suposição posteriormente). Um cálculo rápido mostra que 1/26 = 0,0384. Convertendo isso em porcentagem saberemos que cada letra tem 3,84% de chance de ser a letra selecionada aleatoriamente.
Como aqui não fugimos da matemática e valentemente a enfrentamos, há uma equação para essa pergunta. Vejamos:
Esta equação calcula H, que é o símbolo usado para entropia. Para o nosso alfabeto, a equação ficaria assim:
E agora temos a resposta: terei que fazer uma MÉDIA de 4.7004 perguntas para determinar a letra selecionada aleatoriamente no alfabeto.
Mais formalmente, diríamos que existem 4.7004 ‘bits de entropia’.
Se você aplicar esta matemática a um único caractere selecionado aleatoriamente a partir dos diferentes conjuntos de caracteres que existem, você obterá o seguinte:
Binário (0, 1) -> H = 1 (1 bit de entropia)
Terei que fazer uma pergunta para determinar se o valor selecionado aleatoriamente é 1 ou 0.
Decimal (0-9) -> H = 3,32193 (3,2193 bits de entropia)
Terei que fazer uma média de 3,32193 perguntas para determinar o número selecionado aleatoriamente (0-9).
Hexadecimal (0-9, A-F) -> H = 4.000
Terei que fazer quatro (4) perguntas para determinar seu valor (a-f, 0-9)
Alfabeto maiúsculo e minúsculo (a-z, A-Z) -> H = 5,7004
Terei que fazer uma média de 5.7004 perguntas para determinar sua letra selecionada aleatoriamente (a-z, A-Z).
Todos os caracteres ASCII imprimíveis (incluindo espaço) -> H = 6,5699
Terei que fazer uma média de 6.5699 perguntas para determinar seu valor selecionado aleatoriamente.
Vamos desenvolver isso um pouco mais. Os números acima são para uma ÚNICA letra selecionada aleatoriamente. E se eu pedisse para você escolher duas (2) letras aleatoriamente? Agora, adivinhando uma letra de cada vez, quantas tentativas, em média, eu precisaria para descobrir as duas? A resposta é aditiva, o que significa que você só precisa adicionar a entropia para cada letra. Se a entropia de uma única letra minúscula é 4,7004, a entropia de duas letras selecionadas aleatoriamente é 4,7004 + 4,7004. Isso é 9.4008 perguntas para determinar as duas letras (assumindo a-z, como em nosso exemplo original). Se eu pedisse a você para selecionar uma seqüência de dez (10) caracteres aleatórios, seria necessária uma média de 47,004 perguntas (4,7004 * 10) para adivinhar todos eles.
Tudo bom, tudo bem, mas isso presume que sou capaz de adivinhar apenas um valor de cada vez. Se você escolhesse aleatoriamente 10 letras do alfabeto, eu poderia adivinhar a primeira em cerca de 4,7 tentativas, a segunda em 4,7 tentativas, a terceira em 4,7 tentativas e assim por diante. Mas no mundo real, não é assim que se adivinha senhas (um caractere por vez). Um invasor terá que adivinhar corretamente todos os dez valores de uma só vez para determinar as letras selecionadas aleatoriamente. Isso é, obviamente, uma coisa muito mais difícil de fazer. Mas quão difícil? Para descobrir, vamos voltar à pergunta original que fiz:
O que é mais forte, uma senha aleatória de 8 caracteres que potencialmente usa todo o conjunto de caracteres ASCII (maiúsculas, minúsculas, números, caracteres especiais ( incluindo um espaço)) ou uma senha aleatória de 10 caracteres que usa apenas letras maiúsculas e minúsculas?
Bem, se seu conjunto de caracteres tiver 26 letras minúsculas (az), 26 caracteres maiúsculos (AZ), e sua senha tiver 10 caracteres, haverá 5210 combinações possíveis de letras (26 caracteres (az) + 26 caracteres ( AZ) = 52 caracteres). Esse é um número grande. 144.555.105.949, 057.000 (144,5 quatrilhões), para ser exato ..
Então, para resumir esses valores:
Número de caracteres no conjunto de caracteres (a-z, A-Z): 52
Número de caracteres na senha: 10
Número total de combinações possíveis de sequências de 10 caracteres: = 52^10 = 144.555.105.949.057.000
É aqui que a magia entra em ação:
Qual é a entropia de um único caractere no conjunto completo de caracteres alfa (a-z, A-Z)? Já determinamos que é 5.7004.
Qual é o tamanho da sequência de caracteres selecionada aleatoriamente? 10 caracteres.
Qual é a entropia de uma string de 10 caracteres usando o conjunto de caracteres alfa maiúsculos / minúsculos? 5,7004 * 10 = 57,004
O que é 257,004 ? São 144.555.105.949.057.000 !!! Caramba!!! É o mesmo número que 5210!!!
Sua string de 10 caracteres, maiúsculas / minúsculas (senha) tem 57,004 bits de entropia. Supondo que um invasor acertaria a string em 50% de todas as suposições possíveis, estimamos que ele / ela terá que fazer 72.277.552.974.528.300 suposições (sim, em média) antes de adivinhar sua string de 10 caracteres.
Para dizer isso de forma mais significativa: Uma senha de 10 caracteres maiúsculos / minúsculos tem 57,004 bits de entropia.
Então, quantos bits de entropia nossa senha concorrente tem? É uma senha de 8 caracteres que utiliza o conjunto completo de caracteres ASCII (incluindo um espaço). Se você voltar ao meio desta postagem, verá que um caractere selecionado aleatoriamente do conjunto completo de caracteres ASCII tem 6,5699 bits de entropia. Isso significa que uma senha de 8 caracteres selecionada aleatoriamente nesse intervalo terá 52.559 (8 * 6.5699) bits de entropia.
Para resumir os valores das senhas de 8 caracteres:
Número de caracteres no conjunto de caracteres (a-z, A-Z, 0-9, todos os caracteres especiais, incluindo espaço): 95 Número de caracteres na senha: 8 Número total de combinações possíveis de sequências de 8 caracteres: = 958= 6.634.204.312.890.620 (6,63 quatrilhões)
E vemos que a magia é real:
Qual é a entropia de um único caractere no conjunto de caracteres ASCII completo (incluindo espaço)? Já determinamos que é 6,5699.
Qual é o tamanho da sequência de caracteres selecionada aleatoriamente? 8 caracteres.
Qual é a entropia de uma string de 8 caracteres usando o conjunto de caracteres alfa maiúsculos e minúsculos? 6,5699 * 8 = 52,559
O que é 252.559? É 6.634.204.312.890.620 !!! Caramba, de novo !!! É o mesmo número que 958!!!
Nossa senha de 10 caracteres em maiúsculas / minúsculas tem 57,004 bits de entropia.
Nossa senha de conjunto de caracteres ASCII completa de 8 caracteres tem 52.559 bits de entropia.
Quanto mais bits de entropia uma senha possui, mais forte ela é. E, isso é importante, pois um único bit de entropia representa um aumento EXPONENCIAL na resistencia da senha. Há uma grande diferença entre a força de nossas duas senhas (4,445 ordens de magnitude); isso não é trivial. É algo enorme.
Então, por que usar a entropia como a expressão da força (resistência) da senha? Os gurus da teoria da informação podem certamente dar palestras por dias sobre essas questões, mas há uma resposta simples: os humanos são realmente péssimos para lidar com grandes números. Basta ver como lembramos números de telefone, endereços IP, números de cartão de crédito e números de CPF para evidenciar nossa repulsa por grandes números. Se houver uma maneira de simplificar a expressão de um valor, sempre optaremos por ela. Afinal, o que é mais fácil de dizer e entender ?:
Minha senha tem 5210 possibilidades vs 958 possibilidades. ou; Minha senha tem 57,004 bits de entropia vs 52,559 bits de entropia.
Com certeza você achará esta última forma mais agradável.
Quanto maior o número de bits de entropia de uma senha, mais forte ela tem o potencial de ser. Eu uso a palavra “potencial” aqui porque há muitas nuances nessa discussão que podem tornar esses números um reflexo impreciso da força da senha. A principal delas é o fato de que a maioria das senhas são geradas por humanos, não por geradores de números aleatórios. Os humanos são muito, muito ruins em gerar aleatoriedade. Somos terrivelmente péssimos nisso. Isso significa que a equação usada acima, que assume que cada caracter tem uma probabilidade igual de ser selecionado, não é tão precisa quando é uma pessoa que está escolhendo as letras. Quando invasores, com auxilio do poder de computação, começam a fazer suposições realmente boas sobre como as senhas estão sendo criadas (permitindo que eles excluam certos valores, por exemplo), a entropia pode cair muito rapidamente. Isso é não é bom.
É frequente acontecer que um dos sistemas de uma organização pode suportar o uso do conjunto de caracteres ASCII completo ao definir senhas, enquanto outro pode suportar apenas senhas alfanuméricas. Quantos bits de entropia uma senha deve ter para ser adequadamente segura? Quão longa uma senha alfanumérica deve ser para ser tão forte quanto uma senha que usa o conjunto completo de caracteres? Essas são perguntas muito importantes, especialmente quando se trata de uma política corporativa de senhas. Especificar o comprimento da senha pode ser uma medida inadequada de resistencia; especificar requisitos de entropia de senha tem o potencial de ser uma expressão muito mais consistente dos requisitos de segurança. Não tenho uma citação aqui, mas muitas organizações gostam de ter 80 bits de entropia ou mais. Nos dias de hoje, isso é muita entropia. Cheque novamente em alguns anos e certamente veremos que essa declaração se tornou falsa (pela Lei de Moore).
Uma observação final: há muitas variáveis que devem ser discutidas ao explorar o assunto “senhas”. Complexidade, comprimento e entropia são todos ótimos itens para se entender, mas outros fatores podem ser tão importantes quanto. Por exemplo, quais mecanismos subjacentes suas senhas empregam? Qual algoritmo de hash? As senhas são “salgadas”? Há algum tipo de mecanismo de compatibilidade com versões anteriores habilitado (NTLM, etc.)? Essas coisas influenciam a discussão tanto quanto a entropia e podem ter um grande impacto em quanto esforço um invasor terá de fazer para adivinhar a senha. É um grande tópico, digno de muita reflexão e reflexão cuidadosa. A entropia é um ótimo lugar para começar… mas não é a única coisa a se considerar.
O bom professor Einstein, de formação determinística, inicialmente teve problemas em aceitar a mecânica quântica, em função de seus paradoxos inescrutáveis à época. O fenômeno quântico que mais intrigava Einstein era o emaranhamento (entanglement) entre duas partículas, que forçosamente o levava a concluir que a informação podia ser transmitida a uma velocidade maior que a da luz.
Resumidamente, o emaranhamento quântico significa que várias partículas estão ligadas de tal forma que a medição do estado quântico de uma partícula determina os possíveis estados quânticos das outras partículas. Essa conexão não depende da localização das partículas no espaço (!). Mesmo se você separar duas partículas emaranhadas por bilhões de quilometros, a mudança de estado de uma partícula induzirá uma mudança de estado imediata na outra. (*)Contudo, mesmo que o emaranhamento quântico pareça transmitir informação instantaneamente, já se provou em anos recentes que ele não viola a velocidade da luz e nem a física relativística porque não há “movimento” através do espaço.
Concepção artística de partículas emaranhadas
Essa Ação Fantasmagórica à Distância (que Einstein chamava de spooky action at distance) sempre me mistificou, o que fez com que ao longo dos anos eu inventasse vários experimentos mentais tentando negá-la, invalidá-la, ou ao menos explicá-la (pelo menos para mim). Não que eu seja teimoso ou rejeite a ciência ou algo assim. Apenas é dificil para mim, como foi para Einstein, abrir mão do meu querido mundo determinístico, onde a causa sempre precede o efeito. Entretanto, depois das descobertas dos últimos 30 anos eu estou preparado para tentar viver nesta dura existência indeterminada, aleatória, já que a realidade finalmente se mostra assim. Uma das tentativas de fazer a AFD se acomodar em minha estrutura mental é esta:
Prepare duas partículas para que elas estejam emaranhadas com os seus respectivos spins orientados um para cima (UP) e um para baixo (DOWN). Coloque cada particula em uma caixa lacrada e dê uma caixa para Alice e uma para Bob. Alice e Bob são informados de que as suas caixas contêm ou uma partícula com spin UP ou uma partícula com spin DOWN.
Alice deve pegar a sua caixa e levar para Marte, enquanto Bob fica na Terra.
Ambos fazem um acordo para abrir sua respectiva caixa – e medir (observar) seu conteúdo – às 12:00 UTC (ou outro tempo acordado) em 1º de abril de 2023 (tempo suficiente para Alice chegar a Marte e se acomodar confortavelmente).
Quando chega a hora, Alice abre a sua caixa para descobrir que ela contém uma partícula de spin UP. Ao verificar este fato, ela imediatamente – fantasmagoricamente – saberá que a partícula de Bob, na Terra, tem spin DOWN. Ela não precisa receber uma mensagem de rádio para saber.
Voilà! É isso! Não há nada de mais, certo? A AFD se realizou nesse exato momento. Alice tem a informação muito antes que ela possa ser transmitida por uma chamada de rádio. O único ponto negativo é que ela não poderia usar essa informação para qualquer coisa. O universo assim manteve suas características clássicas, enquanto a Mecânica Quantica foi também satisfeita!
Digamos que Alice, para aproveitar a sua situação (12 minutos preciosos de tempo que o sinal leva entre Marte e a Terra), recebeu uma ordem secreta para apertar um botão para disparar mísseis também secretos em órbita da terra contra algum inimigo de seu país, caso o spin de sua partícula fosse UP (como de fato ocorreu). Para estar de acordo com com a fluxo causal, é preciso considerar que a ordem para o lançamento dos mísseis já estava codificada no sistema quântico também emaranhado de Alice-Bob, e esteve lá o tempo todo. Portanto, nenhuma causalidade foi violada.
Agora é o momento em que tomo consciência de que posso estar completamente errado.
Conceitos não intuitivos
Mesmo os físicos quânticos têm um problema com a teoria quântica devido, em parte, à maneira como as informações são processadas nos cérebros das pessoas. É por isso que alguns especialistas não conseguem comunicar adequadamente suas próprias teorias. É preciso entender que a neurologia, a psicologia e a sociologia desempenham um papel nisso; em outras palavras a percepção, a cultura e a lingüística.
Eu sempre me inclinei para o entendimento de que uma “observação” – ou medição se você quiser – acontece toda vez que duas particulas (ou dois sistemas quânticos) interagem, já que sabemos que todas as interações têm o poder de provocar o colapso da função de onda [esse fato também é a base do – ou pelo menos está implícito no – experimento que motivou esta digressão, que é o teste do Argumento do Amigo de Wigner – ver Google].
Eu pessoalmente tenho problemas em aceitar a consciência como a causação da realidade, porque essa abordagem levanta mais problemas do que resolve. Além disso, as teorias da consciência contemporâneas obviamente não explicam a acima referida interação entre duas partículas e nem as “observações” (percepção da realidade) idênticas realizadas por diferentes espécies animais, com variados graus de inteligência/consciência. Por exemplo, uma lula reagirá com um movimento, assim como eu, se a água for perturbada pela presença de um tubarão. Isso parece sugerir que as duas espécies são capazes de efetuar a mesma medida empírica, independentemente de outras considerações psicológicas e/ou neurais.
O fato é que, confrontados com o Teorema de Bell, nós racionalistas tendemos a procurar consolo no superdeterminismo, a ideia de que todos os possíveis emaranhamentos quânticos já estavam codificados no momento do Big Bang (o que não deixa de ser outro ponto na tão sonhada reconciliação entre Mecânica Quântica e Relatividade Geral).
Há muitos debates complicados acontecendo agora sobre o Twitter e seu papel no discurso público. Essas discussões são importantes, mas também não devemos esquecer um princípio muito básico e claro: quaisquer que sejam suas políticas sobre quem pode e não pode postar ou como postar, é de fundamental importância que o Twitter não exija que os usuários executem software não-livre para usar o site.
Infelizmente, no dia 15 de dezembro, 2020, o Twitter removeu sua interface web “legada”. Ao contrário de seu app cliente padrão muito maior e mais complexo, a interface legada não usava javascript proprietário (ou qualquer javascript).
Até o ano passado, a Fundação Software Livre (FSF) podia tolerar o uso do Twitter por causa dessa interface legada. Enquanto a interface estava ativa nós encaminhávamos os usuários do software gratuito para ela ou a outros aplicativos gratuitos de terceiros. O fato de o Twitter estar removendo o acesso a essa interface significa que os usuários são agora forçados a usar o JavaScript não gráfico do site (se eles não tiverem um desktop ou cliente móvel dedicado), impedindo os navegadores que respeitam a liberdade como o GNU ICECAT de postar para o serviço.
Mas por que usar o Twitter em primeiro lugar, se sabemos que ele tem esses problemas? Como qualquer instituição de caridade pode atestar, engajar os usuários em mídias sociais é uma das maneiras principais de espalhar sua mensagem.
O mesmo é verdade para a liberdade de software. Precisamos estar falando de software livre nos lugares onde os usuários não estão comprometidos com o software livre – não seremos bem sucedidos se formos apenas à nossa própria câmara de eco, ou continuar pregando aos convertidos. É importante que os ativistas estejam atingindo as pessoas nessas redes sociais, mesmo que tenhamos reservas sobre como usá-las. O Twitter tem sua participação em questões sociais; precisamos incluí-lo em nossa estratégia de mensagens. Somos, no entanto, cuidadosos para garantir que você não seja obrigado a seguir o FSF no Twitter, a fim de receber notícias ou atualizações. Tudo o que publicamos também é publicado em plataformas baseadas em princípios de software livre, incluindo Mastodon e GNU Social.
Independentemente de qualquer classificação, no âmbito do software livre a regra é clara: você não pode ser obrigado a usar software não-livre (como JavaScript, PDF, etc) para usar redes sociais.
Como a interface “Legada” (a que não depende do javascript não dirigido pelo Twitter) foi removida, aqueles que se importam fortemente com sua liberdade devem agora dar passos adicionais para usar a plataforma e manter sua autonomia ao mesmo tempo. Na FSF, usamos uma versão ajustada da ferramenta Rainbowstream para GNU / Linux, personalizada por nosso administrador de sistemas sênior Ian Kelling. O script que Ian escreveu nos permite chamar programaticamente a Rainbowstream, bem como o utilitário de toot para mastodon, o cliente Diaspy para DiSpora, e um script de enrolamento que usamos para postar na nossa instância social GNU, https://status.fsf.org.
Graças a alguma colagem “bash” de Ian, somos capazes de fazer posts para esses serviços de uma só vez (o que é chamado de ‘bridging’), e também anexar imagens aos nossos posts. Esta configuração funcionou bem para nós por quase um ano. (*)Se você precisar de um app cliente gratuito para o Twitter, recomendamos o Rainbowstream ou os clientes móveis disponíveis no repositório Android do F-Droid da liberdade, como Twidere.
Embora tenhamos trabalhado de uma maneira a que a equipe de campanhas possa postar no Twitter sem comprometer nossa liberdade, isso não significa que a FSF não seja afetada pela “deprecação” da antiga interface. Como não aconselhamos usar software incompleto em qualquer contexto, tivemos que fazer algumas alterações na nossa página “Compartilhar” e remover o link para nosso perfil do Twitter dos e-mails que enviamos.
Queremos que os usuários espalhem a mensagem de software livre e aprendam sobre nós na mídia social, mas como clicar em um link para o Twitter agora envolve a execução de Javascript não grátis, não queremos apontar as pessoas para qualquer coisa que sabemos eticamente condenável
Problemas “user-hostis” como estes são a razão de o FSF apoiar serviços de rede descentralizados onde quer que possamos. Fizemos isso antes, como em 2008, quando fomos a uma série de uma cúpulas sobre serviços de rede que culminou na publicação da declaração de Franklin Street. O foco da declaração na promoção de serviços descentralizados e na liberdade frente a vigilância corporativa e governamental a granel permanecem parte da nossa estratégia de campanhas. O Twitter pode hoje ter a maioria dos usuários de qualquer rede de microblogging de seu tipo, mas a longo prazo, plataformas descentralizadas, como Mastrodon ou Peertube, prevalecerão. Até mesmo Jack Dorsey do Twitter reconheceu o apelo dessas redes, que são baseadas na participação descentralizada. Continuamos esperançosos de que o Twitter apoiará a descentralização e, ao mesmo tempo, priorizará a liberdade de software.
Sendo uma rede de mídia social tão popular, há uma variedade de questões em torno do Twitter e o que ele significa para a web. Não devemos deixar essa complexidade obscurecer o que não é complexo: o Twitter não deve exigir que ninguém use software não livre para participar do site. Permitir que seus usuários acessem o serviço e mantenham sua liberdade ao mesmo tempo é a linha-base da aceitabilidade, mas a partir daí, existem ainda outras etapas em que o Twitter pode assumir a direção certa, como, por exemplo, estimular um futuro promissor para as iniciativas de descentralização.
Desmontar seu próprio silo e se tornar um entre muitos “nós” da rede descentralizada pode ser sem precedentes a partir de um ponto de vista comercial ou de desenvolvimento, mas também seria sem precedentes em termos do respeito pela liberdade do usuário que isso demonstraria.
2) Estamos também envolvidos em um projeto de Mensagens Instantâneas decentralizadas usando o protocolo XMPP. Estamos adquirindo domínios e capacidade em servidores para a empreitada. O serviço é desenvolvido com o nome provisório “Verbat”. Em breve teremos notícias.