Uma postagem visual para suavizar o mais vital de todos os fins de semana da história brasileira. Minha exploração da arte digital baseada em Difusão Latente continua.
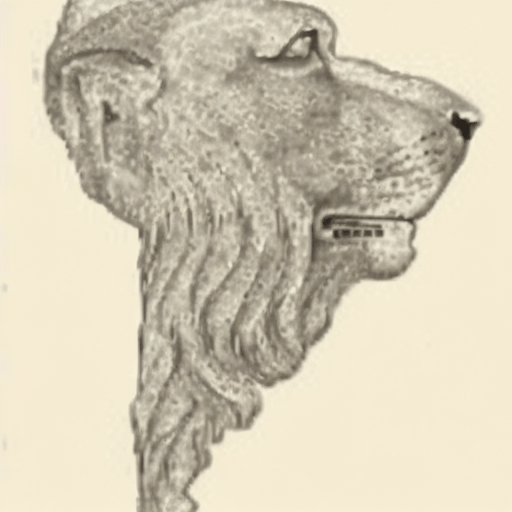
Meu pequeno logotipo é uma linda obra de arte, que chegou às minhas mãos na adolescência e que tenho até hoje. É uma charge de jornal – estrangeiro – do início do século 19, cujo o autor eu ainda não identifiquei, mas sigo procurando.
A arte, sobre a qual ainda falarei mais, mostra um leão exibindo seu perfil direito, em atitude heráldica “couchant”, habilidosamente inscrito no contorno da América do Sul. Um autêntico achado geométrico. É uma imagem evocativa de um Brasil grande e forte, estendendo seu olhar sobre o Atlântico sul.
É uma imagem que resume as aspirações da nação quando eu era jovem. É também uma imagem austera, que se pretende heráldica ao invés de fruto de design; vai contra o pós modernismo vigente, mas aqui no blog essa é exatamente a ideia.
Este blog existe por causa desta imagem; foi olhando para ela em pensamento profundo que me inspirei. “A voz do leão”, para tentar falar de tecnologia e ciência para a lusofonia, com um ‘modicum’ de profundidade – sem dar muita bola para o estilo superficial preferido nas redes sociais — como as pessoas fazem nos centros avançados do mundo. O Brasil é o Leão.
Eu quis fazer variações para poder usar a imagem em outros contextos que exijam um ‘look’ mais contemporâneo — com resultados medianamente animadores. Lancei mão da Stable Diffusion e, abusando da engenharia de prompt, passei algumas horas agradáveis tentando fazer arte. Aproveitei para usar o gadget ‘galeria de slides’ do WordPress pela primeira vez.
Não sei se verei esse Brasil grande, que faz tecnologia, que lança foguetes e satélites e junta à elite material do mundo. Se depender da classe política que aí está eu duvido muito que cheguemos lá. Foi sob a batuta do Ministro da Tecnologia, um aviador e astronauta formado por um instituto de tecnologia, que eu testemunhei o maior [talvez o único] desmonte deliberado de políticas tecnológicas do estado brasileiro em toda história [a começar do programa espacial, que se encontra desativado desde 2003].
Que o Brasil possa se reencontrar a partir das eleições de amanhã. Boa sorte a todos.
Se você não está prestando atenção ao que está acontecendo com o súbito aparecimento da Difusão Estável, você está perdendo um momento realmente interessante na história da tecnologia.
Tudo começou quando há dez dias, em 22 de agosto, a start-upStability.ai abriu o acesso à sua plataforma de síntese de imagem chamada “Stable Diffusion” – uma arquitetura de difusão latente semelhante ao DALL-E 2 do OpenAI e ao Imagen do Google, treinada com milhões de imagens extraídas da web. Desde então a tecnologia tem desfrutado uma contínua explosão de interesse.
Ao contrário do conteúdo deepfake baseado em autoencoder, ou das recriações da figura humana que podem ser alcançadas por Neural Radiance Fields (NeRF) e Generative Adversarial Networks (GANs), os sistemas baseados em difusão aprendem a gerar novas imagens adicionando ruído às imagens usadas como fontes. A reiteração desse processo ensina o sistema como fazer imagens plausíveis – e até foto-realistas – a partir apenas desse ruído.
Modelos baseados em difusão aprendem a reconstruir fotos adicionando ruído a imagens “não contaminadas” e observando a relação elas e a imagem “contaminada” à medida que mais ruído é adicionado. Imagem: Google
Com a repetição do processo, o modelo começa a entender as “relações latentes” entre fontes altamente difusas e suas versões nítidas e de maior resolução. Depois de bem treinado, um modelo de difusão latente do tipo “texto-para-imagem” pode então “recuperar” imagens, separando-as do ruído de base usando prompts de texto como guias para quais elementos recuperar.
Em apenas alguns dias, houve uma explosão de inovação em torno deste processo. As coisas que as pessoas estão criando são absolutamente surpreendentes.
Tenho acompanhado o subreddit r/StableDiffusion e seguido o fundador da Stability, Emad Mostaque, no Twitter.
Minhas experiências
No início desta semana eu comecei a fazer experimentos com a tecnologia. O mínimo que posso dizer é que gerar imagens a partir de texto é um jogo totalmente novo.
Com os modelos “texto-para-imagem”, as habilidades linguísticas adquirem muita importância, à medida que a precisão conceitual na composição do chamado “prompt” vai determinar o resultado final do trabalho. No estágio atual da tecnologia, o prompt deve ser composto em inglês. Eu suponho que uma interface em português vai surgir em algum momento – farei minha contribuição na medida do possível.
Minhas explorações mostradas aqui foram feitas na plataforma onlinebeta.dreamstudio.ai (atualmente grátis). A conta no site permite a geração de 200 imagens, antes de começar a monetizar. Já existem muitos outros sites parecidos, e novos aparecem todo dia.
Canalizei meu Roger Dean interior e comecei a esboçar algumas coisas. Depois de uma manhã eu já tinha uma pequena coleção para curtir e mostrar:
Um Sonho de São Paulo
Eu gosto do estilo matte paint, e minha primeira ideia foi investigar como São Paulo apareceria como um cenário a laBlade Runner.
Prompt usado: A dream of Sao Paulo city, Caspar David Friedrich, matte painting, artstation HQ
No prompt eu estabeleço alguns parâmetros/atributos que eu gostaria que a imagem tivesse:
Dream, indicando uma atmosfera onírica; São Paulo city, o objeto central, Caspar Friedrich, replicando o estilo do artista homólogo, Matte painting, para dar a textura, Artstation HQ, para invocar o estilo do studio Artstation [games, mídia].
São Paulo Dream
Neste ponto o leitor já percebeu que eu gosto de São Paulo e curto uma atmosfera onírica, com elementos pós-apocalípticos.
Prompt Usado: A dream of Sao Paulo, a distant galaxy, Caspar David Friedrich, matte painting, trending on artstation HQ
Nave Alien Gigante
Prompt usado: gigantic extraterrestrial futuristic alien ship in brand new condition, not ruins, hyper-detailed, artstation trending, world renowned artists, antique renewal, good contrast, realistic color, cgsociety, greg rutkowski, gustave dore, Deviantart
Roma Alienígena
Prompt usado: Julius Caesar, alien roman historic works, ruins, hyper-detailed, world renowned artists, historic artworks society, good contrast, realistic color, cgsociety, Greg Rutkowski, Deviantart
Um Rio de Janeiro de Sonho
Prompt usado: Rio de Janeiro, fuzzy, dreamy, world renowned artists, good contrast, pastel color, Greg Rutkowski, Deviantart
Rio Hipgnosis
Aqui eu tentei replicar o estilo do já citado Roger Dean, e do estúdio Hipgnosis, famoso pelas capas de discos das grande bandas de rock nos anos setenta, como Yes, Pink Floyd, Led Zeppelin, e muitos outros. Note a silhueta do Pão de Açúcar, quase imperceptível. Definitivamente Lisérgico.
Prompt usado: Rio de Janeiro, sketchy, dreamy, world renowned artists, good contrast, pastel color, Roger Dean, Hipgnosis
Transilvania
Aqui eu recebi o valoroso input de minha mulher, ligada ao mundo das bruxas e das brumas, que sempre me apoia em minhas desventuras digitais. A ideia era fazer Drácula aparecer no cenário, mas vejo que será preciso maior empenho na engenharia do prompt.
Prompt usado (composto por Marília Gião): Dracula castle on a mountain, at dusk, matte paint, Transylvania dream, David Friedrich, chariots with horses, hyper detailed, deviantart
É mesmo uma coisa incrível. Imagine ter um artista conceitual multi habilidoso ao seu dispor, cujo único propósito na existência é interagir com você e materializar suas fantasias visuais mais loucas. Tudo a um custo muito baixo.
Você pode executar a difusão estável em seu próprio computador, em um ambiente virtual python, se tiver as inclinações técnicas para configurá-lo [é preciso placa gráfica compatível com CUDA – tipicamente Nvidia] . Posso dar algumas indicações nos comentários, se alguém tiver interesse. Em serviços online como Replicate ou Hugging Face você pode ainda usar a biblioteca “imagem-para-imagem” – que está chegando também à interface do DreamStudio que usamos aqui.
Há muito mais acontecendo. A melhor descrição que vi até agora de um processo iterativo para construir uma imagem usando Stable Diffusion vem de Andy Salerno: 4.2 Gigabytes, ou: Como desenhar qualquer coisa. Nestes experimentos eu usei partes dos prompts de Andy.
E há muito mais por vir.
As inescapáveis questões éticas
As questões éticas levantadas por esses sistemas precisam ser enfrentadas e resolvidas. São questões difíceis.
A difusão estável foi treinada com milhões de imagens extraídas da web. Essas imagens são protegidas por direitos autorais. Não estou qualificado para falar sobre a legalidade disso. Pessoalmente, estou mais preocupado com a moralidade.
O Stable Diffusion v1 Model Card tem todos os detalhes de especificação, mas para resumir, ele usa um dataset LAION-5B (5,85 bilhões de pares de imagem-rótulo) e seu subconjunto Laion-aesthetics v2 5+ (um conjunto de aproximadamente 600 Milhões de pares). Essas imagens foram retiradas da web.
O modelo final tem cerca de 4,2 GB de dados – um blob binário de “floating points”. O fato de se poder comprimir uma quantidade tão grande de informação visual em um volume tão pequeno é, em si, um feito fascinante. Contudo, de novo, as pessoas que criaram essas imagens não foram consultadas sobre seu consentimento.
Para além disso, como já como discutimos no blog em outra postagem [link], o modelo pode ser visto como uma ameaça direta ao meio de subsistência de milhões de profissionais pelo mundo afora. Eu mesmo fui um desenhista ilustrador em meu primeiro emprego. Hoje eu não teria chance de começar. O vídeo e o áudio seguirão o mesmo caminho. Ninguém esperava que as IAs criativas viessem tão rapidamente para ceifar os empregos dos artistas, mas aqui estamos!
Há também implicações [negativas] para o mercado de arte — e, em breve, do fonográfico, além do cinema.
Nasce uma Nova profissão: a Engenharia de Prompt
Como tentei mostrar, e como você mesma(o) pode verificar se resolver praticar a técnica no link que forneci, o background pessoal influenciará muito no sucesso. As pessoas que vão exercer essa atividade em um nível profissional elevado nas agências de criação terão que se aprofundar na observação e no estudo da linguagem.
Além da precisão linguística, os parâmetros envolvidos na composição do prompt, para um resultado artístico perfeitamente controlado, exigem conhecimento técnico, senso de estilo e conhecimento histórico. Quanto mais palavras-chave relacionadas estiverem envolvidas na composição maior será o controle do artista sobre o resultado final. Exemplo: o prompt
Uma cidade futurista distante, cheia de prédios altos dentro de uma enorme cúpula de vidro transparente, No meio de um deserto árido cheio de grandes dunas, Raios de sol, Artstation, Céu escuro cheio de estrelas com um sol brilhante, Escala maciça, Neblina, Muito detalhado, Cinematográfico, Colorido
é mais sofisticado do que simplesmente
Uma cidade cheia de prédios altos dentro de uma enorme cúpula de vidro transparente
Note que a densidade conceitual, portanto a qualidade, do prompt depende muito do background cultural e linguístico da pessoa que faz a composição. De fato, um prompt de qualidade se assemelha muito a uma cena de cinema descrita em um roteiro/storyboard [a propósito, lá se vão os Production Designers, junto com os concept artists, graphic designers, set designers, costume designers, lighting designers…].
Na tentativa de monetizar os frutos da nova tecnologia, os empreendedores da Internet serão forçados pela mão invisível do mercado de trabalho a se aprofundar nos conhecimentos linguísticos. Será um efeito colateral benigno, penso eu, considerando estado atual da Internet. Talvez isso leve a uma melhor articulação das ideias no ambiente da rede.
Assim como influenciadores do YouTube têm talento para lidar com os aspectos visuais das interações humanas, os aspirantes à engenharia de prompt terão que se destacar em farejar as nuances da expressão humana. Eles têm grande potencial para ser os novos profissionais descolados da economia digital, assim como foram os web designers, e depois os influencers — que, com o fim das redes sociais, agora tendem a perder relevância.
Para se diferenciar, os engenheiros de prompt terão que ser ávidos leitores e praticantes de semiótica/semiologia.
Umberto Eco e os estruturalistas poderão voltar à moda.
Indistinguível da magia
Apenas alguns meses atrás, se eu tivesse visto alguém criar essas imagens em um programa de TV, ou em um vídeo do YouTube, eu teria resmungado sobre essas mistificações, grosseiras mesmo para padrões da TV e da Internet (sorry).
A ficção científica é real agora. Modelos generativos de aprendizagem de máquina estão aqui, e a taxa com que eles estão melhorando é absolutamente irreal. Eu digo isso tendo um histórico de ceticismo quanto ao “hype” e às possibilidades dessa modalidade de AI. Vale a pena prestar atenção ao que eles são capazes de fazer, como estão se desenvolvendo, e ao impacto que eles terão na sociedade.